
Wiktionnaire:Wikidémie/septembre 2018
Lieu d’entraide, de réflexion et de proposition.
Voir aussi les questions sur les mots, les questions techniques.
Actualités du Wiktionnaire d’août 2018[modifier le wikicode]

Les Actualités d’août vous offrent de nouvelles statistiques et une nouvelle présentation plus élégante encore ! Plongeons au-delà du Wiktionnaire francophone, vers l’ensemble des projets lexicographiques Wiktionary, grâce à un nouvel outil dédié ! À la surface : deux dictionnaires spécialisés sur le vocabulaire du droit, et autour flottent les sujets qui ont intéressé les journaux cet été. Nous sommes allés à la pêche aux brèves et les illustrations proviennent de la campagne estivale de photographie des régions lointaines !
- Le prochain numéro n’attend que vous !
- Les numéros précédents à lire sur la plage.
- Vous pouvez même vous abonner pour être notifié des prochaines publications et faire savoir que vous lisez régulièrement cette publication communautaire !
Huit personnes ont écrit ou relu ce numéro et vous êtes les bienvenus pour faire partie des personnes qui écriront les prochains numéros ![]() Noé 1 septembre 2018 à 00:08 (UTC)
Noé 1 septembre 2018 à 00:08 (UTC)
LexiSession de septembre[modifier le wikicode]
Bonjour,
Ce mois-ci, nous vous proposons de nous intéresser à la surdité et à l’audition car le 23 septembre aura lieu la Journée mondiale des sourds. Nous pourrions probablement créer enrichir collectivement un thésaurus sur la surdité ou sur l’audition, en s’inspirer des nombreux thésaurus créés par nos collègues anglophones pour enrichir les pages qui tournent autour de ce sujet !
L’idée de la LexiSession est de proposer un thème par mois à l’ensemble des Wiktionnaires afin d’avancer conjointement sur un même sujet et d’apprendre par l’observation des pratiques des autres, et par le contenu créé sur un thème que l’on découvre, dans d’autres langues. Cette initiative est ouverte à tous et les sujets peuvent être proposé sur cette page de Meta !
Si le thème vous intéresse, vous pouvez indiquer ce que vous faites autour de celui-ci durant le mois ou à la fin. Si vous le pouvez, allez prévenir les autres Wiktionnaires dans leurs langues, pour qu’ils se joignent à l’aventure ! Les LexiSessions ont besoin de relais ! ![]() Noé 1 septembre 2018 à 00:13 (UTC)
Noé 1 septembre 2018 à 00:13 (UTC)
- J’ai commencé de compléter les listes de dérivés et autres dans les entrées wikt:fr:sourd et wikt:fr:surdité. Alphabeta (discussion) 1 septembre 2018 à 17:46 (UTC)
- Bonjour Noé, je ne suis pas sûr que la description du système auditif humain ait sa place dans le thésaurus sur la surdité. Il est impliqué dans les problèmes de surdité mais pas que. Il vaudrait peut-être mieux faire un thésaurus sur l’audition qui renverrait vers la surdité, non ? Jpgibert (discussion) 3 septembre 2018 à 14:00 (UTC)
- Je suis d’accord, nous ne pourrons pas cerner le thème de la surdité avec un seul thésaurus ! Et merci d’ailleurs à Alphabeta puis à Cbyd pour vous être attaqué à ce thème
 Noé 3 septembre 2018 à 14:19 (UTC)
Noé 3 septembre 2018 à 14:19 (UTC)
- Je suis d’accord, nous ne pourrons pas cerner le thème de la surdité avec un seul thésaurus ! Et merci d’ailleurs à Alphabeta puis à Cbyd pour vous être attaqué à ce thème
- Bonjour Noé, je ne suis pas sûr que la description du système auditif humain ait sa place dans le thésaurus sur la surdité. Il est impliqué dans les problèmes de surdité mais pas que. Il vaudrait peut-être mieux faire un thésaurus sur l’audition qui renverrait vers la surdité, non ? Jpgibert (discussion) 3 septembre 2018 à 14:00 (UTC)
Tableau de bord Cognate : Anomalie des résultats[modifier le wikicode]
![]() @Pamputt et @Lea Lacroix (WMDE) : Bonjour, la mise à jour de « I miss you » révèle une anomalie en effet tout les mots qui étaient présent dans 25, 24, 23, 22, 21 … Wiktionnaires, ne le sont plus que dans 1 à 3 wiktionnaires de moins. Comme si plusieurs Wiktionnaires n’existaient tout simplement plus ou qu’il y avainte eu des suppressions de masse. Si on compare la liste User:Otourly/IMISSU on va de 25 à 18 Wiktionnaires, tandis que la liste WCD donne une liste de 23 à 17 Wiktionnaire. L’ordre semble aussi mélangé. D’ordinaire les nombres ne peuvent qu’augmenter. D’ailleurs la liste anglaise que j’ai suivie aussi ne présente pas cette incohérence. Souci de calcul ? Otourly (discussion) 2 septembre 2018 à 08:29 (UTC)
@Pamputt et @Lea Lacroix (WMDE) : Bonjour, la mise à jour de « I miss you » révèle une anomalie en effet tout les mots qui étaient présent dans 25, 24, 23, 22, 21 … Wiktionnaires, ne le sont plus que dans 1 à 3 wiktionnaires de moins. Comme si plusieurs Wiktionnaires n’existaient tout simplement plus ou qu’il y avainte eu des suppressions de masse. Si on compare la liste User:Otourly/IMISSU on va de 25 à 18 Wiktionnaires, tandis que la liste WCD donne une liste de 23 à 17 Wiktionnaire. L’ordre semble aussi mélangé. D’ordinaire les nombres ne peuvent qu’augmenter. D’ailleurs la liste anglaise que j’ai suivie aussi ne présente pas cette incohérence. Souci de calcul ? Otourly (discussion) 2 septembre 2018 à 08:29 (UTC)
- Ça ressemble plus à un souci de calcul/bogue car les liens sur le Wix anglophone valident bien le nombre d’interwikis précédent la mise à jour. Otourly (discussion) 2 septembre 2018 à 08:53 (UTC)
 @Otourly :, du coup je ne suis pas sûr d’avoir compris, pourquoi le Wiktionnaire anglophone serait correct tandis que le reste (quoi précisément) serait erroné. Pamputt [Discuter] 2 septembre 2018 à 10:55 (UTC)
@Otourly :, du coup je ne suis pas sûr d’avoir compris, pourquoi le Wiktionnaire anglophone serait correct tandis que le reste (quoi précisément) serait erroné. Pamputt [Discuter] 2 septembre 2018 à 10:55 (UTC)
- @Pamputt : Je n’ai pas la réponse. Le classement donné pour frwikt est tout chamboulé entre la mise à jour de ~1:30 UTC et celle de ~7:30 UTC actuellement visible. N’importe quel mot de la liste n’affiche pas le bon nombre d’interwikis par rapport à la réalité et la mise à jour de 1:30. Par contre pour enwikt, I miss you n’a pas tout chamboulé ni tout déclassé. Otourly (discussion) 2 septembre 2018 à 11:01 (UTC)
- Hmmm, si c’est juste sur une mise à jour, attendons une ou deux nouvelles mises à jour pour voir si ça s’améliore tout seul. Pamputt [Discuter] 2 septembre 2018 à 11:16 (UTC)
- La mise à jour de 13.30 UTC ne conteint pas l’anomalie. Otourly (discussion) 2 septembre 2018 à 14:43 (UTC)
- Hmmm, si c’est juste sur une mise à jour, attendons une ou deux nouvelles mises à jour pour voir si ça s’améliore tout seul. Pamputt [Discuter] 2 septembre 2018 à 11:16 (UTC)
Entrées lexicales en arabe[modifier le wikicode]
Bonjour à tous,
J'ai un problème sur comment spécifier les Wiktionnaire:Conventions/arabe, par rapport à ce que propose wikt:en:Wiktionary:About Arabic.
Le contexte est que l'arabe s'écrit avec ou sans diacritiques indiquant les voyelles (et autres subtilités), si bien qu'on rencontre en pratique deux types de formes attestées et susceptibles d'être documentées dans le wiktionnaire :
- Une forme sans aucuns diacritiques, « abrégée », telle qu'on peut la lire dans les journaux, genre كلب ;
- Une forme avec diacritiques, « complète », telle qu'on peut la lire dans des manuels scolaires et pour la lecture du Coran, genre كَلَبَ.
La forme sans diacritique peut être ambigüe, dans la mesure où plusieurs mots différents (au-delà de simples flexions) peuvent avoir une forme « abrégée » identique (voir à ce sujet Wiktionnaire:Conventions/arabe/Diacritiques). Jusqu'ici, pas de problème métaphysique, pour ce que j'en comprends :
- À partir du moment où les deux formes se rencontrent, les deux peuvent (doivent) avoir une entrée dans le Wiktionnaire ;
- Ces deux formes sont en pratique des alternatives graphiques l'une de l'autre, désignant la même entité sous des codages de représentation différents, donc doivent renvoyer l'une à l'autre ;
- La forme principale (celle à laquelle est attaché un sens lexical) est a priori la forme avec diacritiques, « complète ». L'autre peut se contenter d'un revois sur la forme principale.
... ou pas ? s'il y a des critiques à ce niveau (notamment le #3), merci de les signaler.
Bon. Ensuite, il y a un problème potentiel sur la forme de l'entrée principale.
- Dans le cas d'un verbe, tout le monde s'accorde à ce que l'entrée de référence soit à la troisième personne masculin singulier - pas de problème.
- Mais dans le cas d'un nom ou d'un adjectif, c'est plus problématique. La "norme" sur en: est de supprimer la dernière voyelle dans l'entrée, ce qui en fait une forme générique mais non attestée en tant que telle.
Donc, pour une entrée genre كَلْب, l'entrée n'a pas de voyelle sur la dernière consonne, c'est donc une forme qui n'est jamais attestée.
- Le wiktionnaire en: ne propose que l'entrée en:wikt:كلب sans diacritiques, donc tout est sur la même page et la question ne se pose pas.
- Mais un certain nombre de wiktionnaires proposent une entrée كَلْب, sans désinence ni voyelle finale, donc une forme non attestée en tant que telle.
J'aurai tendance à proposer pour une entrée lexicalenon pas une forme tronqée, mais avec diacritiques (entrée principale sans désinence) une forme qui existe effectivement, donc de type كَلْبٌ (kalbũ) /kal.bun/ (nominatif indéfini) plutôt qu'une forme artificielle.
...Des idées et.ou suggestions sur cette question ? Je pense qu'il faudrait mobiliser sur ce point les contributeurs maîtrisant l'arabe à un niveau suffisant.
Bonnes réflexions, Micheletb (discussion) 2 septembre 2018 à 17:31 (UTC)
- Je me contenterai de rappeler des règles générales, applicables aussi pour l’arabe :
- les différentes formes doivent chacune avoir une page avec un contenu (sans utiliser de redirections)
- pourquoi vouloir imposer une forme principale ? Je suppose qu'il y a une question de préférence personnelle pour écrire avec ou sans diacritiques. Chaque contributeur doit donc pouvoir privilégier la forme qu’il préfère, par exemple en créant deux pages (une par forme) et en mettant dans la définition de la forme non privilégiée Voir … (mais on peut aussi, bien sûr, ne privilégier aucune des deux formes et faire une page complète pour chacune). Si un autre contributeur veut remplacer ce Voir par une vraie définition parce qu’il privilégie, lui, cette écriture, il doit pouvoir le faire. Mais à l’inverse, il ne faut jamais remplacer une vraie définition par un Voir, car ça complique la consultation par un lecteur qui consulterait cette page précise (nécessiterait un clic en plus, c’est important). Et en plus, ça pourrait induire des guerres d’édition entre contributeurs avec des préférences différentes.
- je ne comprends pas deux remarques qui semblent contradictoires : La "norme" sur en: est de supprimer la dernière voyelle dans l'entrée, ce qui en fait une forme générique mais non attestée en tant que telle. et Le wiktionnaire en: ne propose que l'entrée en:wikt:كلب sans diacritiques, donc tout est sur la même page et la question ne se pose pas..
- Je suis d’accord qu’il vaut mieux ne décrire que des formes complètes (et décrire toutes les formes complètes). Mais, au cas où il serait classique dans beaucoup de dictionnaires de décrire des formes tronquées (je ne sais pas si c’est le cas), alors ça voudrait dire que certains lecteurs peuvent avoir cette habitude, et que nous pourrions donc les décrire aussi, en plus, en pensant à eux. Lmaltier (discussion) 2 septembre 2018 à 18:13 (UTC)
- Bonjour,
- A/ S'agissant des formes avec ou sans diacritiques (habillées ou nues, pour faire court) :
- L'idée est effectivement de donner une entrée pour chaque forme (ce que ne fait pas en:, d'ailleurs).
- Le problème de la forme nue se voit facilement sur en:wikt:كلب : la forme de base "klb" correspond en réalité à quatre mots apparentés par le sens : كَلْبْ (kalb) /kalb/ chien (nc) ; كَلَبْ (kalab) /ka.lab/ rage (nc) ; كَلِبَ (kaliba) /ka.li.ba/ devenir enragé (verbe) ; كَلِبْ (kalib) /ka.lib/ enragé (adj). Donc, parce que les formes nues ne permettent pas de distinguer les différents mots, ils se retrouvent avec l'équivalent de quatre mots sur une même page (et encore ce n'est pas la pire).
- Donc le fait de choisir la forme avec diacritiques (habillée) comme entrée permet de limiter le sens d'une entrée (habillée) à un seul mot, et de limiter une entrée nue à un rôle de désambiguïsation.
- « il ne faut jamais remplacer une vraie définition par un Voir », certes, mais une forme comme en:wikt:كلب n'a par elle-même ni sens ni définition (ce que montre bien la structure de la page). Ce sont des formes écrites abrégées, exactement comme le seraient des formes en sténographie pour écrire le français. Parce qu'elles suppriment l'information sur la vocalisation, ces formes rendent homographes un grand nombre de mots, mais ça n'en fait pas un "même mot". Donc, paradoxalement, la forme nue est le déguisement d'une forme habillée.
- A2/ Si on veut en plus que toutes les formes attestées aient une entrée (ce qui est légitime) la situation devient encore plus inextricable avec les formes nue, parce que les flexions d'un terme ne donnent pas toujours les mêmes formes dénudées, et une forme dénudée peut correspondre à différents modes de flexion, et pas nécessairement du même mot ni même (parfois) du même radical.
- B/ Ensuite, la question est comment écrire ces formes avec diacritiques, comment ça s'articule avec les flexions, et c'est ça mon vrai problème aujourd'hui.
- La convention universelle en arabe est de mettre comme forme vedette d'un verbe la troisième personne masculin singulier de l'accompli. Donc, quand on dit que كَلِبَ (kaliba) /ka.li.ba/ = "devenir enragé", ça signifie en réalité littéralement "il est devenu enragé". C'est conventionnel, et je n'ai pas de problème avec ça.
- Le problème est pour les noms et adjectifs : quelle forme vedette? Toujours sur en:wikt:كلب, on voit pour "chien" dans le tableau "Declension" que la forme "kalb" (retenue une ligne au-dessus comme forme vedette) est qualifiée de "informelle". Ça me gêne de mettre une forme informelle en vedette ; c'est un peu comme si en français pour voilà on mettait v’là comme forme vedette et l'autre comme forme fléchie
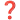 .
.
- C'est même plus compliqué, parce que il n'y a aucune chance qu'une forme même informelle soit écrite comme ça, c'est (pour ce que j'en sais) une invention du Wiktionnaire. « Certains lecteurs peuvent avoir cette habitude » - non. De toute manière ces deux formes ont la même écriture sans diacritique. Donc l'écriture informelle sera de toute manière "klb", et jamais personne n'écrira "kalb" : soit on est informel et il n'y a pas de diacritiques, soit on met des diacritiques et on ne peut pas prétendre être informel, c'est une confusion des genres. D'autre part, tel qu'est réglé le Wiktionnaire, la recherche par mots se fait en ignorant les diacritiques, donc quelle que soit son habitude il se retrouvera de toute manière, au départ, sur la page décrivant les formes "nues", à chercher quelle est la forme habillée qui correspond à son texte.
- Ça ne pose pas de problème de signaler, au sein d'une entrée habillée, que d'une manière générale l'arabe parlé tend à supprimer les suffixes des noms et adjectifs, et donc que toutes les formes fléchies se lisent toutes "kalb" ou "elkalb" (et s'écrivent "klb" ou "âlklb"). Mais prétendre que "kalb" est une forme vedette, c'est pratiquement faire un néologisme à partir d'une forme qui n'existe que dans la prononciation relâchée. Si ce n'est pas solidement justifié, c'est mal.
- C/
- En réalité ça ne fait pas une très grande différence, là où la forme informelle est كَلْبْ (kalb) /kalb/, la forme canonique classique (nominatif singulier indéfini) est كَلْبٌ (kalbũ) /kal.bun/. La différence porte sur la crotte de mouche en haut à gauche, qui est toujours la même pour tous les noms et adjectifs. Bon, sauf pour les diptotes, qui suivent des déclinaisons spécifiques, mais ça permet justement de les identifier d'office.
- Donc : كَلْبْ (kalb) /kalb/ (néologisme) ou كَلْبٌ (kalbũ) /kal.bun/ (grammaticalement correcte) ?
- Micheletb (discussion) 3 septembre 2018 à 04:53 (UTC)
- En ce qui concerne la maitrise de l’arabe, Reda Kerbouche et Reda benkhadra pourront peut-être apporter un éclairage. Pamputt [Discuter] 3 septembre 2018 à 06:07 (UTC)
- Bonjour tout le monde. @Micheletb : j'aimerais bien t'aider, mais si on se connecte en live chat sa sera genial, puisque comme sa je serai à l'aise pour t'explique et trouver des solutions. Si tu veux contacte-moi par wiki mail en premier.--Reda Kerbouche (discussion) 3 septembre 2018 à 06:25 (UTC)
Si les formes incomplètes ne sont pas quelque chose de classique dans les dictionnaires, alors il ne faut pas les mettre, c’est clair. En ce qui concerne les formes habillées ou nues, il ne faut pas se laisser entraîner sur une discussion sur ce qui serait le mieux, le plus logique, pour être utilisé comme forme principale. Il suffit de constater que les deux formes sont utilisées par écrit, et ne pas retirer d’informations utiles des pages sous prétexte que ce ne serait pas la forme principale. En effet, je suis persuadé que c’est en partie une question de préférence personnelle. Je connais quelqu’un qui préfèrerait l’écriture nue pour l’arabe (il est vrai qu’elle parle persan, pas arabe, et qu’on n’utilise pas les diacritiques en persan, mais c’est pour dire que l’opinion personnelle joue, et que nous devons pas prendre position sous prétexte de logique). Maintenant, chacun doit pouvoir faire comme il veut, mais sans retirer de renseignements utiles déjà présents et utiles au lecteur de la page précise, sous prétexte que c’est déjà dans la page de l’autre forme. Lmaltier (discussion) 6 septembre 2018 à 06:42 (UTC)
Création du thésaurus de l’exil et temps fort autour de l’exposition « Ai Weiwei, Fan-Tan »[modifier le wikicode]
Bonjour, j’ai créé le thésaurus de l’exil en français suite à discussion avec ![]() @Sophiedidacressources :. En résumé, Sophie anime des ateliers avec des migrants, et c’est de là qu’est venu l’idée de ce thésaurus. Plus exactement elle a suggéré cela plutôt que la thématique de la migration elle même par rapport au titre d’un temps fort autour de l’exposition « Ai Weiwei, Fan-Tan » (p. 56) du Mucem. D’ailleurs s’il y a des personnes intéressé par cet événement qui se tiens le dernier week-end de septembre, Sophie serait ravit d’avoir du renfort.
@Sophiedidacressources :. En résumé, Sophie anime des ateliers avec des migrants, et c’est de là qu’est venu l’idée de ce thésaurus. Plus exactement elle a suggéré cela plutôt que la thématique de la migration elle même par rapport au titre d’un temps fort autour de l’exposition « Ai Weiwei, Fan-Tan » (p. 56) du Mucem. D’ailleurs s’il y a des personnes intéressé par cet événement qui se tiens le dernier week-end de septembre, Sophie serait ravit d’avoir du renfort.
En attendant je vous invite à nous aider à améliorer cette ébauche et à encourager Sophie à participer plus avant sur le Wiktionnaire ainsi que d’apporter toutes vos idées sur la manière dont la communauté du Wiktionnaire peut apporter de l’aide sur ce type de démarches.
Bonne journée, Psychoslave (discussion) 5 septembre 2018 à 08:12 (UTC)
- Ce thésaurus dépassant déjà largement son thème, j’ai créé en complément Thésaurus:migration/français pour organiser le vocabulaire autour de ces deux thèmes qui ne désignent pas les mêmes réalités. Je me suis retrouvé avec un terme très polysémique, migration, et j’ai hésité à créer plusieurs thésaurus homographes avec des redirections. Connaissant mal ce vocabulaire, j’ai tout mis dans un seul thésaurus, mais si vous venez aider à développer tout ça, il est possible qu’il faille diviser en plusieurs thésaurus distincts, selon les acceptations du terme Noé 11 septembre 2018 à 09:41 (UTC)
Quels sont les Wiktionnaires les plus reliés au Wix ?[modifier le wikicode]
Coucou,
Avant toutes choses ces stats n’ont qu’une valeur indicative. Mes sources de données sont le Wiktionary Cognate Dashboard d’une part dont la mise à jour est fréquente, et Wikiscan pour les totaux qui semble dans les choux car pour lui le Wix n’a pas dépassé les 3 300 000. Bref les pourcentages sont juste une indication. Certains nombres vous étonneront ! Otourly (discussion) 5 septembre 2018 à 19:17 (UTC)
| Version linguistique | Pages en commun avec le Wix | Total de pages sur le Wiktionnaire local source Wikiscan |
Pourcentage pages en commun/nombre de pages totales sur le projet |
|---|---|---|---|
| malgache | 1015526 | 5107058 | 19,8847555676869 |
| anglais | 1007164 | 5758491 | 17,4900681445886 |
| polonais | 227745 | 630643 | 36,1131416665213 |
| russe | 182542 | 984334 | 18,5447216087222 |
| néerlandais | 174238 | 673557 | 25,8683377947226 |
| espagnol | 161434 | 860628 | 18,7576978671389 |
| grec | 156887 | 461340 | 34,0068062600251 |
| coréen | 155018 | 290122 | 53,4320044670863 |
| chinois | 154617 | 836296 | 18,4883103590116 |
| hongrois | 150731 | 348937 | 43,1971960554484 |
| finnois | 143976 | 362482 | 39,7194895194796 |
| allemand | 141099 | 715629 | 19,7167806223616 |
| ido | 140013 | 284658 | 49,1863920915625 |
| suédois | 135406 | 655626 | 20,6529332271753 |
| kurde | 116998 | 633940 | 18,4556898129161 |
| vietnamien | 113965 | 233067 | 48,8979563816413 |
| italien | 110478 | 432547 | 25,5412706596046 |
| cherokee | 91198 | 194419 | 46,9079668139431 |
| japonais | 83826 | 211140 | 39,7016197783461 |
| portugais | 78408 | 247816 | 31,6396035768473 |
| catalan | 75675 | 356105 | 21,2507546931383 |
| birman | 70133 | 118437 | 59,2154478752417 |
| espéranto | 67850 | 98082 | 69,1768112395751 |
| estonien | 66761 | 127480 | 52,3697834954503 |
| turc | 59931 | 330568 | 18,129704024588 |
| tchèque | 58051 | 103812 | 55,9193542172389 |
| norvégien | 57509 | 142697 | 40,3014779567896 |
| limbourgeois | 49247 | 114765 | 42,9111662963447 |
| thaï | 48560 | 169281 | 28,6860309190045 |
| tamoul | 47646 | 349365 | 13,6378858786656 |
| lituanien | 46223 | 616184 | 7,50149306051439 |
| roumain | 45574 | 145056 | 31,4182108978601 |
| arabe | 45017 | 65108 | 69,1420409166308 |
| indonésien | 39481 | 130423 | 30,2715011922744 |
| serbe | 35529 | 218645 | 16,2496283930572 |
| malayalam | 31273 | 129807 | 24,0919210828384 |
| azéri | 30137 | 55467 | 54,3332071321687 |
| basque | 28773 | 54090 | 53,1946755407654 |
| serbo-croate | 28612 | 911549 | 3,13883290969547 |
| galicien | 28234 | 53308 | 52,9639078562317 |
| danois | 25759 | 38550 | 66,8197146562905 |
| [[:simple:Special:Statistics|]] | 23701 | 26077 | 90,8885224527361 |
| kannara | 23625 | 264087 | 8,9459155505572 |
| laotien | 23450 | 37656 | 62,2742723603144 |
| arménien | 23439 | 261992 | 8,94645638034749 |
| occitan | 22462 | 45463 | 49,4072102588918 |
| ouzbek | 22427 | 116602 | 19,2338038798648 |
| télougou | 19699 | 105994 | 18,5850142460894 |
| kirghiz | 17691 | 28144 | 62,8588686753837 |
| ourdou | 17269 | 25277 | 68,3190252007754 |
| fidjien | 17029 | 31305 | 54,3970611723367 |
| persan | 16654 | 97936 | 17,0049828459402 |
| croate | 16310 | 32678 | 49,9112552787808 |
| tagalog | 13869 | 15390 | 90,1169590643275 |
| slovaque | 13278 | 24783 | 53,5770487834403 |
| breton | 12643 | 38475 | 32,8602988953866 |
| gallois | 11618 | 24116 | 48,1754851550838 |
| tadjik | 10936 | 29589 | 36,9596809625199 |
| latin | 10394 | 23946 | 43,4059968261923 |
| hindi | 9783 | 183142 | 5,341756669688 |
| bulgare | 9764 | 27710 | 35,2363767592927 |
| ukrainien | 9603 | 36627 | 26,2183635023343 |
| asturien | 8758 | 18817 | 46,5430196099272 |
| islandais | 8721 | 22283 | 39,1374590494996 |
| afrikaans | 7437 | 20360 | 36,5275049115914 |
| swahili | 7006 | 13974 | 50,1359667954773 |
| minnan | 6803 | 21706 | 31,3415645443656 |
| samoan | 6744 | 4281 | 157,533286615277 |
| corse | 6662 | 9417 | 70,7443984283742 |
| norvégien (nynorsk) | 5944 | 12125 | 49,0226804123711 |
| letton | 5608 | 11066 | 50,6777516717875 |
| frison | 5083 | 13554 | 37,501844473956 |
| mongol | 4939 | 9306 | 53,0732860520095 |
| albanais | 4910 | 7539 | 65,1280010611487 |
| géorgien | 4617 | 8211 | 56,2294483010596 |
| slovène | 4537 | 7787 | 58,2637729549249 |
| sicilien | 4251 | 18721 | 22,7071203461354 |
| luxembourgeois | 4130 | 7298 | 56,5908468073445 |
| kazakh | 4104 | 5776 | 71,0526315789474 |
| wallon | 4004 | 23280 | 17,1993127147766 |
| khmer | 3849 | 4168 | 92,3464491362764 |
| volapük réformé | 3521 | 23384 | 15,0573041395826 |
| bas allemand | 3404 | 7939 | 42,8769366418945 |
| pachto | 3338 | 25512 | 13,0840388836626 |
| bengali | 3326 | 10936 | 30,4133138258961 |
| bosniaque | 3023 | 7142 | 42,3270792495099 |
| javanais | 2894 | 60718 | 4,76629665008729 |
| macédonien | 2749 | 4188 | 65,639923591213 |
| sanskrit | 2436 | 5978 | 40,7494145199063 |
| nahuatl | 2145 | 7052 | 30,4169030062394 |
| biélorusse | 2099 | 3963 | 52,9649255614434 |
| malais | 1989 | 3664 | 54,2849344978166 |
| tatare | 1931 | 1850 | 104,378378378378 |
| hébreu | 1800 | 18226 | 9,87600131680018 |
| aragonais | 1618 | 2565 | 63,0799220272905 |
| gaélique irlandais | 1613 | 2724 | 59,2143906020558 |
| interlingue | 1446 | 1671 | 86,5350089766607 |
| maltais | 1319 | 1765 | 74,7308781869688 |
| vénitien | 1230 | 2284 | 53,8528896672504 |
| vieil anglais | 1145 | 2150 | 53,2558139534884 |
| somali | 1130 | 1631 | 69,2826486817903 |
| kachoube | 1124 | 1530 | 73,4640522875817 |
| ouïghour | 1078 | 1520 | 70,921052631579 |
| gaélique écossais | 1050 | 1461 | 71,8685831622177 |
| wolof | 977 | 2310 | 42,2943722943723 |
| interlingua | 839 | 1053 | 79,6771130104464 |
| aroumain | 821 | 1272 | 64,5440251572327 |
| turkmène | 809 | 4589 | 17,6291130965352 |
| maori | 680 | 910 | 74,7252747252747 |
| kalaallisut | 674 | 864 | 78,0092592592593 |
| aymara | 669 | 886 | 75,5079006772009 |
| féroïen | 552 | 851 | 64,8648648648649 |
| sindhi | 547 | 1775 | 30,8169014084507 |
| haut-sorabe | 543 | 4148 | 13,0906460945034 |
| népalais | 531 | 354 | 150 |
| lojban | 459 | 726 | 63,2231404958678 |
| lingala | 450 | 673 | 66,8647845468054 |
| pendjabi de l’Ouest | 402 | 9276 | 4,33376455368693 |
| nauruan | 387 | 556 | 69,6043165467626 |
| amharique | 387 | 217 | 178,341013824885 |
| mannois | 386 | 457 | 84,4638949671772 |
| gujarati | 377 | 460 | 81,9565217391304 |
| cornique | 352 | 442 | 79,6380090497738 |
| zoulou | 341 | 599 | 56,9282136894825 |
| oromo | 279 | 335 | 83,2835820895522 |
| cingalais | 265 | 1199 | 22,1017514595496 |
| sotho du Sud | 261 | 1343 | 19,4341027550261 |
| pendjabi | 259 | 11432 | 2,26557032890133 |
| hindi des Fidji | 244 | 1128 | 21,6312056737589 |
| kinyarwanda | 241 | 366 | 65,8469945355191 |
| marathe | 228 | 1684 | 13,5391923990499 |
| inuktitut | 217 | 258 | 84,108527131783 |
| divehi | 190 | 180 | 105,555555555556 |
| soundanais | 160 | 295 | 54,2372881355932 |
| haoussa | 136 | 260 | 52,3076923076923 |
| guarani | 125 | 1742 | 7,17566016073479 |
| tok pisin | 125 | 151 | 82,7814569536424 |
| sango | 122 | 111 | 109,90990990991 |
| quechua | 121 | 303 | 39,9339933993399 |
| inupiaq | 105 | 143 | 73,4265734265734 |
| zhuang | 104 | 179 | 58,1005586592179 |
| swazi | 84 | 292 | 28,7671232876712 |
| tswana | 83 | 106 | 78,3018867924528 |
| yiddish | 71 | 124 | 57,258064516129 |
| tsonga | 60 | 359 | 16,7130919220056 |
| tigrigna | 46 | 115 | 40 |
| kashmiri | 28 | 56 | 50 |
| oriya | 21 | 108593 | 0,0193382630556297 |
| assamais | 7 | 16 | 43,75 |
- C’est marrant, on a que 16% de mots en commun avec le Wiktionnaire en serbe tandis qu’on a environ 50% d’entrées en commun avec celui en croate
 Pamputt [Discuter] 5 septembre 2018 à 21:10 (UTC)
Pamputt [Discuter] 5 septembre 2018 à 21:10 (UTC)
- Je vois surtout que le Wiktionnaire pourrait sans trop de mal avoir 100% de « simple ». Otourly (discussion) 6 septembre 2018 à 05:47 (UTC)
- Pour simplewikt, ça m’a frappé aussi mais il semble qu’il y ait quelques problèmes avec ce Wiktionnaire pour la création de stats fiables. Pamputt [Discuter] 6 septembre 2018 à 06:00 (UTC)
- Je vois surtout que le Wiktionnaire pourrait sans trop de mal avoir 100% de « simple ». Otourly (discussion) 6 septembre 2018 à 05:47 (UTC)
![]() @Pamputt : J’ai mis à jour les données me basant cette fous sur les pages de contennu des wikis. Ces données sont fraîches d’un peu moins d’une heure (pour le haut du tableau). Ce qui interpelle ce sont les pourcentages > à 100%. Ça voudrait dire que le Wiktionnaire est plus lié qu’il n’y a de contenu… Otourly (discussion) 9 septembre 2018 à 17:55 (UTC)
@Pamputt : J’ai mis à jour les données me basant cette fous sur les pages de contennu des wikis. Ces données sont fraîches d’un peu moins d’une heure (pour le haut du tableau). Ce qui interpelle ce sont les pourcentages > à 100%. Ça voudrait dire que le Wiktionnaire est plus lié qu’il n’y a de contenu… Otourly (discussion) 9 septembre 2018 à 17:55 (UTC)
Valoriser les vidéos de mots exprimés en langue des signes française[modifier le wikicode]
Salut,
Wikimédia France a établi un partenariat avec Signe De Sens (SDS) pour bénéficier de téléversement de vidéos illustrant l’expression de mots dans la langue des signes française. Un premier versement par [[commons:Category:Files supported by Wikimedia France - Elix |lot d’une centaine de vidéos est déjà présent sur Commons]]. Au total c’est 19 000 vidéos qui devraient pouvoir être ainsi récupérés. Sur leur propre dictionnaire Elix, SDS propose aussi des lectures kinésiques de ses vidéos.
Je vous invite donc à suggérer vos idées sur la manière dont nous pourrions intégrer ce matériel lexicologique au sein du Wiktionnaire. Cela pourrait être une simple inclusion d'image, mais nous pourrions aussi développer un modèle qui se chargerait d’une intégration pertinente.
À vous commentaires, Psychoslave (discussion) 6 septembre 2018 à 10:43 (UTC)
- Créer un nouveau nom de domaine ? Si ça se trouve le même geste n'a pas la même signification dans les autres langues des signes ? Otourly (discussion) 6 septembre 2018 à 11:46 (UTC)
Si on veut savoir le signe correspondant à un mot, il suffit d’inclure la vidéo dans la page du mot. Mais si on veut savoir le sens d’un signe qu’on voit, c’est plus difficile : ça implique un codage conventionnel des signes, et on pourrait faire des pages consacrées à ces codes. Je ne sais pas ce qui existe exactement à ce sujet comme conventions bien répertoriées. Et il se peut que ces conventions dépendent des langues, ce qui compliquerait encore les choses. Pour répondre à Otourly, oui, il y a différentes langues des signes, l’idéal serait de les décrire toutes. Lmaltier (discussion) 6 septembre 2018 à 18:03 (UTC)
- Oui il existe bien différentes langues des signes. Qu'est-ce qui serait le plus pertinent du coup selon vous ? Ajouter la vidéo dans la section français du mot concerné, ou créer une section LSF dédié ? --Psychoslave (discussion) 6 septembre 2018 à 20:39 (UTC)
- Comme je le dis plus haut, ajouter la vidéo dans la section du mot concerné + dans la mesure du possible, créer des pages pour les mots en langue des signes, ce qui implique que ces mots puissent être écrits, donc qu’ils soient encodés. Lmaltier (discussion) 7 septembre 2018 à 05:12 (UTC)
- Comme il peut y avoir plusieurs vidéos correspondant à différents sens, ou à des signes "synonymes", ou à des langues des signes différentes (LSF, LSFB, LSQ, pour le français), il est plus clair de mettre les vidéos dans leur propre section "Langue des signes". Je recommanderais également de ne les lister que dans les pages de leur langue "parente" (quand ça fait sens...). — Dakdada 7 septembre 2018 à 14:01 (UTC)
- J’avais cru que l’idée était peut-être, dans la page cheval, de mettre une section de langue de signe au même niveau que la section Français. Je ne pensais pas que c’était une bonne idée, car cheval n’est pas un mot en langue des signes. Mais mettre une section au même niveau que Synonymes ou Traductions, pas de problème. Lmaltier (discussion) 7 septembre 2018 à 16:38 (UTC)
- Comme il peut y avoir plusieurs vidéos correspondant à différents sens, ou à des signes "synonymes", ou à des langues des signes différentes (LSF, LSFB, LSQ, pour le français), il est plus clair de mettre les vidéos dans leur propre section "Langue des signes". Je recommanderais également de ne les lister que dans les pages de leur langue "parente" (quand ça fait sens...). — Dakdada 7 septembre 2018 à 14:01 (UTC)
- Comme je le dis plus haut, ajouter la vidéo dans la section du mot concerné + dans la mesure du possible, créer des pages pour les mots en langue des signes, ce qui implique que ces mots puissent être écrits, donc qu’ils soient encodés. Lmaltier (discussion) 7 septembre 2018 à 05:12 (UTC)
Ce qui est intéressant dans ce dépôt, c’est qu’il y a des vidéos pour les termes, mais également des vidéos contenant leurs définitions. A voir maintenant comment créer les pages d’entrées en LSF. Notamment parce qu’actuellement, elles ne peuvent pas être recherchée à partir d’une capture vidéo d’un signe, ce qui serait très bien mais demanderait un développement logiciel assez balaise, je pense. J’avais déjà un peu réfléchi au sujet des signes dans une page de brouillon perso, mais nous pourrions initier un projet collectif si plusieurs personnes se montrent intéressées ![]() Noé 7 septembre 2018 à 06:43 (UTC)
Noé 7 septembre 2018 à 06:43 (UTC)
Accompagner au mieux la tenue d’un atelier[modifier le wikicode]
J’ai récemment eu la chance d’entrer en contact avec ![]() @geugeor : qui souhaite réaliser des sessions de formations pour une association qui fait dans la promotion d'une langue locale camerounaise, le Ghomala. Son idée est d'enrichir le wiktionnaire. Il est donc preneur de tout conseils pratiques concernant la réalisation de ce projet. Ce serait de début d'une grande collaboration car le Cameroun compte plus de 200 langues locales !
@geugeor : qui souhaite réaliser des sessions de formations pour une association qui fait dans la promotion d'une langue locale camerounaise, le Ghomala. Son idée est d'enrichir le wiktionnaire. Il est donc preneur de tout conseils pratiques concernant la réalisation de ce projet. Ce serait de début d'une grande collaboration car le Cameroun compte plus de 200 langues locales !
Il a déjà eu l’occasion d’œuvrer sur des enregistrements en Ghomala avec ![]() @Benoît Prieur : et
@Benoît Prieur : et ![]() @Pamputt : pendant Wikiindaba, mais ne connaissais pas encore Lingua Libre.
@Pamputt : pendant Wikiindaba, mais ne connaissais pas encore Lingua Libre.
Détails pratiques :
- durée de 3 jours
- se tiendra en novembre
- a priori 20 personnes participeront, mais le nombre exacte ne sera pas connu avant le 3e dimanche de septembre.
Les sujets sur lesquels les conseils sont expressément les bienvenus :
- les éléments pratiques qu'il faut pour la formation (dictaphones,...)
- les comment fonctionne Lingua Libre et comment s’en servir en formation
- quel est l'idéal en terme d'effectifs
Bien sûr si vous avez d’autres suggestions, n’hésitez pas à les communiquer. ![]() De plus geugeor sera présent à la Wikiconvention francophone en octobre à Grenoble.
De plus geugeor sera présent à la Wikiconvention francophone en octobre à Grenoble.
J’en ai également discuté avec ![]() @Lyokoï : qui m’a indiqué qu’il serait partant pour faire une session de formation à distance au besoin.
@Lyokoï : qui m’a indiqué qu’il serait partant pour faire une session de formation à distance au besoin.
Merci par avance pour votre aide, Psychoslave (discussion) 6 septembre 2018 à 11:06 (UTC)
J’ai recontacté ![]() @geugeor :, qui m’a indiqué que l’atelier accueillera au final un quinzaine de personnes. En terme de préparatif, je lui ai suggéré :
@geugeor :, qui m’a indiqué que l’atelier accueillera au final un quinzaine de personnes. En terme de préparatif, je lui ai suggéré :
N’hésitez pas à fournir des liens vers d’autres ressources qui peuvent aider. Pour ce que j'en ai saisi, l’atelier a deux objectifs :
- enregistrer la prononciation de mots, et en français, et dans une langue locale, sur la base d’identification d’images. Je ne crois pas que ce soit possible avec Ligua Libre actuellement, ce serait une extension intéressante à mettre en œuvre il me semble.
- documenter les mots, y compris leurs transcriptions phonétiques
Nous avons notamment abordé la question de l’écriture des langues locales et les transcriptions phonétiques, et des problèmes de saisie au clavier. Pour les transcriptions, je lui ai indiqué qu’un clavier spécifique n’est pas nécessaire, que sous le formulaire d’édition il y avait possibilité de sélectionner les caractères spéciaux à intégrer. Pour l’alphabet phonétique international (API), c'est tout à fait suffisant, un clavier spécifique n'est pas indispensable.
Pour l’écriture des langues locales, je ne vois pas le Ghomala’ dans la liste des alphabets proposés, et il semble effectivement comprendre des caractères spécifiques. Du côté des claviers physiques, je ne sais pas ce qu'il existe. Sur les téléphones portables, il semble qu'il y ai des claviers virtuelles adaptés. Ce serait super de pouvoir ajouter le Ghomalaʼ à la liste des alphabets proposés avant que cet atelier ai lieu, cela dit il me semble que l’ensemble des caractères utilisés sont aussi présent dans l’API.
Je laisse ![]() @geugeor : compléter ou corriger mes éventuelles erreurs, et invite chacun à faire part de ses suggestions. --Psychoslave (discussion) 21 septembre 2018 à 09:49 (UTC)
@geugeor : compléter ou corriger mes éventuelles erreurs, et invite chacun à faire part de ses suggestions. --Psychoslave (discussion) 21 septembre 2018 à 09:49 (UTC)
- Pour ajouter un alphabet, c’est plutôt rapide, il suffit de faire la demande sur WT:QT, en donnant le plus de détails possibles. — Lyokoï (Discutons
 ) 21 septembre 2018 à 10:56 (UTC)
) 21 septembre 2018 à 10:56 (UTC)
- Merci beaucoup Psychoslave, je confirme tout ce que tu as écrit. En même temps, l'idée pour moi à travers cette plateforme est que nous puissions contribuer à la structuration du programme en prenant en compte tous les éléments matériels et logiciels pour le bon déroulement de la formation.--Geugeor (discussion) 21 septembre 2018 à 19:31 (UTC)
Read-only mode for up to an hour on 12 September and 10 October[modifier le wikicode]
Lire ce message dans une autre langue • Aidez-nous à traduire dans votre langue
La Fondation Wikimedia va tester son centre de données secondaire. Cela permettra de s'assurer que Wikipédia et les autres wikis Wikimedia peuvent rester en ligne même après une catastrophe. Pour être certain que tout fonctionne, le département Technologie de Wikimedia doit réaliser un test planifié. Ce test permettra de prouver qu'il est possible de passer d'un centre de données à un autre. Cela demande à ce que toutes les équipes soient prêtes à tester et à réparer tout problème imprévu.
L'intégralité du trafic passera au centre de données secondaire le mercredi 12 septembre 2018. Le mercredi 10 octobre 2018, le trafic reviendra au centre de données principal.
Malheureusement, à cause de quelques limitations dans MediaWiki, les modifications de pages devront être arrêtées durant ces changements. Nous nous excusons pour ce dérangement, et nous travaillons à le minimiser dans le futur.
Pendant une courte période, vous pourrez lire les wikis, mais pas les modifier.
- Vous ne pourrez pas effectuer de modification pendant une durée pouvant aller jusqu'à une heure, le mercredi 12 septembre et le mercredi 10 octobre. Le test commencera à 14:00 UTC (15:00 BST, 16:00 CEST, 10:00 EDT, 07:00 PDT, 23:00 JST, et en Nouvelle-Zélande à 02:00 NZST le jeudi 13 septembre et le jeudi 11 octobre).
- Si vous essayez de faire une modification ou de sauvegarder, vous verrez un message d'erreur. Nous espérons qu'aucune modification ne sera perdue durant cette période, mais nous ne pouvons le garantir. Si vous voyez un message d'erreur, merci de patienter jusqu'au retour à la normale. Vous pourrez alors enregistrer votre modification. Mais nous vous conseillons de faire une copie de votre modification avant, au cas où.
Autres effets :
- Les tâches de fond seront ralenties, et certaines pourraient être stoppées. Les liens rouges ne seront pas mis à jour aussi vite que d'habitude. Si vous créez un article qui est déjà lié depuis une autre page, le lien rouge pourrait rester rouge plus longtemps que d'habitude. Certains scripts ayant un temps d'exécution long devront être stoppés.
- Le code sera figé durant les semaines du 10 septembre 2018 et du 8 octobre 2018. Il n'y aura pas de déploiements de code non essentiel.
Ce projet peut être remis à plus tard en cas de nécessité. Vous pouvez consulter le calendrier sur wikitech.wikimedia.org. Tout changement sera annoncé dans le calendrier. Il y aura d'autres annonces à propos de cet événement. Merci de partager ces informations avec votre communauté. /User:Johan(WMF) (talk)
6 septembre 2018 à 13:33 (UTC)
- Ça tombe bien, le 12 septembre n’est pas mon anniversaire. --Ars’ 10 septembre 2018 à 18:59 (UTC)
Bonjour, je suis Classiccardinal[modifier le wikicode]
Quoique banni de tous les sites de la fondation, je me considère toujours comme un administrateur du wix. Je sais, ça énerve, mais je ne vois pas pourquoi des étrangers au projet pourrait me faire virer d'un site où ils ne contribuent pas. Afin de mettre un terme à une situation qui m'agace je demande à être officiellement viré de la liste des admins du Wix, et de la même manière que pour mon admission: avec un vote. 10 voix contre et j'arrête. En dessous je continue. ₡₡
 Pour une procédure utile, qui sera probablement soutenue par Ars’, qui aime bien les procédures utiles Noé 6 septembre 2018 à 20:02 (UTC)
Pour une procédure utile, qui sera probablement soutenue par Ars’, qui aime bien les procédures utiles Noé 6 septembre 2018 à 20:02 (UTC)- Trop tard pour revenir ici. Mais il y a des bannis comme X qui se plaisent bien sur Wikibooks encore aujourd'hui, puisqu'il n'y a aucune discussion sur son livre. JackPotte ($♠) 6 septembre 2018 à 20:59 (UTC)
- Je sais pas qui c'est X. Il est pas sur la liste des Wikimedians banned by the WMF. Je vois pas le rapport avec mézigue.₡₡
 Conserver @Noé, petite précision : je n’adore pas du tout les procédures, surtout quand elles sont procédurières et inutiles.
Conserver @Noé, petite précision : je n’adore pas du tout les procédures, surtout quand elles sont procédurières et inutiles.
- Ah bon, elle est finie l’époque bénie ou tu présentais une candidate d’admin pour qu’il y en ai au moins une dans l’année ? Dommage Noé 15 septembre 2018 à 08:47 (UTC)
- Ah bon, elle est finie l’époque bénie ou tu présentais une candidate d’admin pour qu’il y en ai au moins une dans l’année ? Dommage
?? Cela n’a pas de sens d’être administrateur quand on est interdit de contribution. Lmaltier (discussion) 7 septembre 2018 à 05:08 (UTC)
- C'est incohérent en effet. Après, si c'est pour montrer que nul n'échappe aux règles établies, ça me choque pas. Otourly (discussion) 7 septembre 2018 à 07:17 (UTC)
- Du coup, on fait quoi? Pasque moi, j'suis toujours à fond. PS: je m'excuse: jusqu'à hier, y'avait jamais de pub sur mes liens. Il me semble que ça a changé depuis. Sans doute que quelqu'un se fait désormais du fric sur un cadavre. Gavez vous bien, les vautours.--109.213.96.140 12 septembre 2018 à 19:31 (UTC)
D'ici (à) 2050, 80% des Wiktionnaristes auront plus de 80 ans[modifier le wikicode]
C’est peut-être triste… ou pas. Mais en tous cas ça ne va pas favoriser la réforme de l’accord du participe passé, c’est sûr, une fois…
En passant, on dit
ou
- d’ici à ?
--Ars’ 9 septembre 2018 à 18:21 (UTC)
- N°1, comme "d'ici demain". JackPotte ($♠) 9 septembre 2018 à 20:10 (UTC)
Il n’y a pas à faire de réforme pour l’accord du participe passé, il faut juste corriger les règles fausses enseignées à l’école (et pas dans le sens des Belges), ce n’est pas une réforme. Quand au titre, pour les 80 ans, c’est vraiment n’importe quoi. Lmaltier (discussion) 9 septembre 2018 à 20:20 (UTC)
- j’en aurai un peu plus de 60. Si tout va bien ;-) Otourly (discussion) 10 septembre 2018 à 04:38 (UTC)
- Otourly est un bébé, Otourly est un bébé, Otourly est un bébé !
 --Ars’ 10 septembre 2018 à 18:52 (UTC)
--Ars’ 10 septembre 2018 à 18:52 (UTC)
- Rien à foutre, j'ai pas d'âge.--109.213.96.140 12 septembre 2018 à 19:36 (UTC)
- Otourly est un bébé, Otourly est un bébé, Otourly est un bébé !
Quel intérêt d’indiquer des formes officiellement rejetées ?[modifier le wikicode]
Mimich et moi avons parlé de la note dans citron en espéranto concernant la proposition de réforme rejetée de 1895. Je ne comprends pas pourquoi on indique des formes hypothétiques et officiellement rejetées. C’est inutile et même trompeur. (Et pourquoi parle-t-on de l’ido ?) Si cette proposition de réforme jamais appliquée est importante, il faudrait créer une annexe plutôt que l’expliquer dans plus de 18 000 entrées. Je voudrais retirer toutes ces notes dans l’espace principal. Qu’en pensez-vous ? — TAKASUGI Shinji (d) 10 septembre 2018 à 16:19 (UTC)
- Je suis d’accord. Même s’il ne faut jamais retirer des pages des renseignements corrects et utiles aux lecteurs de la page, il ne faut pas pour autant encombrer les pages avec des choses inutiles. En plus, cela peut faire penser à une campagne pour relancer cette tentative de réforme. Lmaltier (discussion) 10 septembre 2018 à 17:48 (UTC)
- Seul un idiste chevronné pourrait nous dire ce qui est étymologiquement inintéressant pour l’Ido (forme descendante et réformée de l’Espéranto; "ido" = "descendant" en espéranto) dans les formes proposées. La réforme proposée (mais refusée par vote) de 1895 est une des sources de l’ido. Mais on a sans doute pas tout pris et d’autres éléments de réforme viennent surement d’ailleurs. Effacez tout sans discernement sera une perte de données élémentaires et des catégorisations. J’ai déjà commencé une réduction au minimum utile dans les fiches principales en transposant sur la ligne adhoc dans les "références" pour les fiches dans ces catégories. Comme le caractère non voté de la réforme est clairement indiqué , il n’a pas, à mes yeux, de confusion quant aux formes actives (qui sont dans le tableau principal des flexions). --Mimich (discussion) 11 septembre 2018 à 02:50 (UTC)
- Je trouve ces notes inutiles pour l’espéranto. C’est en fait une information pour l’ido et non pour l’espéranto, n’est-ce pas ? Pourquoi pas les déplacer dans des entrées correspondantes en ido ? En outre nous n’utilisons que
{{S}}pour créer des sections. — TAKASUGI Shinji (d) 11 septembre 2018 à 03:35 (UTC)
- Je trouve ces notes inutiles pour l’espéranto. C’est en fait une information pour l’ido et non pour l’espéranto, n’est-ce pas ? Pourquoi pas les déplacer dans des entrées correspondantes en ido ? En outre nous n’utilisons que
- Seul un idiste chevronné pourrait nous dire ce qui est étymologiquement inintéressant pour l’Ido (forme descendante et réformée de l’Espéranto; "ido" = "descendant" en espéranto) dans les formes proposées. La réforme proposée (mais refusée par vote) de 1895 est une des sources de l’ido. Mais on a sans doute pas tout pris et d’autres éléments de réforme viennent surement d’ailleurs. Effacez tout sans discernement sera une perte de données élémentaires et des catégorisations. J’ai déjà commencé une réduction au minimum utile dans les fiches principales en transposant sur la ligne adhoc dans les "références" pour les fiches dans ces catégories. Comme le caractère non voté de la réforme est clairement indiqué , il n’a pas, à mes yeux, de confusion quant aux formes actives (qui sont dans le tableau principal des flexions). --Mimich (discussion) 11 septembre 2018 à 02:50 (UTC)
- Que ce soit dans une section en espéranto ou en ido, si cela offre une information pertinente aux lecteurs elle doit figurer quelque part. Moi je suis plus gêné par des catégories qui n'existent pas Spécial:Catégories_demandées remplies de plus de 1000 entrées. En effet si ces catégories sont des catégories de maintenance, elles doivent être cachées et pas apparaître en lien rouge sur toute les pages. J'aimerai bien qu'on me dise ce que c'est car leur nom n'est pas très clair. Otourly (discussion) 11 septembre 2018 à 08:42 (UTC)
- Pour les catégories, ce sont des compteurs du nombre de verbes pour chaque type de flexion de verbes (modes et temps). Je n’en avait pas fait des catégories de maintenances fixes pour avoir une flexibilité quant à leur pertinence à long terme et me laisser l’occasion de trouver un meilleur nom que "le nom mécanique" si je les gardais. Je vais le formaliser. --Mimich (discussion) 11 septembre 2018 à 11:33 (UTC)
- Quant au passage de l’espéranto à l’ido, il peut se présenter trois scénarios : soit on a simplement suivi la "proposition 1895"; soit on a employé une autre modalité, soit un hybride. Je me demandais la pertinence de transposer cela dans un tableau de transition avec les trois formes en présence : espéranto - proposition 1895 - ido. A placer et dans l’espéranto et dans l’ido. Sachant que parfois l’ido n’est peut-être pas le descendant de l’espéranto ou de la proposition 1895. Un tableau de comparaison absolu, tous scénarios confondus. Qu’en pensez-vous et sous quel type de section le mettre? En créer un nouveau ? --Mimich (discussion) 11 septembre 2018 à 11:33 (UTC)
- Une autre observation, c’est que les formes de la conjugaison de l’ido semble suivre essentiellement la conjugaison des formes apparemment similaires de l’espéranto officiel. Si ce n’est que l’infinitif n’est plus -i mais -ar (-a dans la proposition 1895) et l’impératif est en -ez comme en français (vs -u en espéranto et -an dans la proposition 1895). En espéranto cette forme est commune avec le subjonctif qui n’apparaît dans le tableau que voici pour le verbe idiste "kambrar" : Conjugaison:ido/kambrar. Tout comme dans la proposition 1895, le pluriel des substantifs est -i (-oj en esperanto) et il n’y a pas d’accusatif (contrairement à l’espéranto : -n). --Mimich (discussion) 11 septembre 2018 à 14:46 (UTC)
- Question complètement stupide et hors-sujet, c’est pour ça que je la mets en tout petit : les espérantistes au sens très large seraient-ils les véritables créateurs du concept de fork, 100 ans avant les développeurs ? Je signe pas, c’est trop crétin (inutile d’insister).
- Une autre observation, c’est que les formes de la conjugaison de l’ido semble suivre essentiellement la conjugaison des formes apparemment similaires de l’espéranto officiel. Si ce n’est que l’infinitif n’est plus -i mais -ar (-a dans la proposition 1895) et l’impératif est en -ez comme en français (vs -u en espéranto et -an dans la proposition 1895). En espéranto cette forme est commune avec le subjonctif qui n’apparaît dans le tableau que voici pour le verbe idiste "kambrar" : Conjugaison:ido/kambrar. Tout comme dans la proposition 1895, le pluriel des substantifs est -i (-oj en esperanto) et il n’y a pas d’accusatif (contrairement à l’espéranto : -n). --Mimich (discussion) 11 septembre 2018 à 14:46 (UTC)
L’indication est sans doute exacte, mais pourquoi la mettre en valeur de cette façon (on ne voit que ça) ? On a vraiment l’impression d’une campagne en faveur de cette réforme ancienne refusée. Si la réforme a été refusée et que ce qui est indiqué n’a jamais été utilisé, je continue à penser que c’est inutile de l’indiquer (contrairement à ce qui résulte d’une réforme votée et officiellement recommandée, même pour ce qui n’a jamais été utilisé en pratique). On veut décrire tous les mots, c’est vrai, mais pas ce qui aurait pu être un mot si… Lmaltier (discussion) 11 septembre 2018 à 05:13 (UTC)
- Pour ce que j'en comprends :
- L'information est probablement inutile en espéranto, sauf à justifier d'avoir une section d'espéranto historique (ce qui n'est généralement pas le cas) ; donc à supprimer de la section espéranto.
- Elle correspond probablement à une information étymologique de l'ido, vus les arguments ci-dessus, et dans ce cas : à conserver en tant que telle dans la (sous-)section associée du langage ido.
- Si la section "ido" n'existe pas, il faudra dans ce cas la créer, et y mettre l'info étymologique. Très probablement (à confirmer) le sens en ido peut dans ce cas être décalqué sur la section espéranto.
- L'ensemble me paraît être à la portée d'un traitement automatique (mais hélas pas à la portée de mes connaissances en traitement automatique).
- Micheletb (discussion) 13 septembre 2018 à 17:30 (UTC)
Je suis tout à fait d'accord, j'en avais déjà parlé sur Discussion modèle:eo-conj-intrans. Mettre des formes fictives n'a aucun intérêt, ça encombre juste les pages et ça fait croire au lecteur que ces formes hypothétiques sont beaucoup plus importantes qu'elles le sont en réalité, à savoir totalement inconnues pour l'écrasante majorité des espérantophones — il n'y a que sur le Wiktionnaire français que j'en ai entendu parler. Mutichou (discussion) 14 septembre 2018 à 08:19 (UTC)
- J’ai supprimé les formes hypothétiques dans
{{eo-conj}},{{eo-conj-intacc}}et{{eo-conj-intrans}}. — TAKASUGI Shinji (d) 21 septembre 2018 à 03:11 (UTC)
Je pense que nous sommes presque tous d’accord. Je propose donc la suppression de ces notes (probablement à l’aide de JackBot dressé par JackPotte). — TAKASUGI Shinji (d) 23 septembre 2018 à 07:15 (UTC)
Je pense que la demande n'est pas complète : si le bot retire la note d'une flexion en espéranto, il doit créer la flexion qui était dedans en "ido" ? Et avec quelle source ? JackPotte ($♠) 23 septembre 2018 à 14:25 (UTC)
- Non, je ne comprends pas ça, car ce serait souvent faux. Il faut traiter chaque langue séparément. Lmaltier (discussion) 13 juin 2019 à 05:33 (UTC)
À continuer : Wiktionnaire:Prise de décision/Suppression des informations liées à la réforme rejetée de 1895 en espéranto
Création du verbe embocager[modifier le wikicode]
Bonjour,
Le verbe embocager n’est pas dans le wiktionnaire ! Je ne le fais pas car je me doute qu’il y a un bot pour créer toutes les conjugaisons. Je le laisse donc à qui voudra. Romainbehar (discussion) 10 septembre 2018 à 17:18 (UTC)
- Il y a un bot pour créer les pages des formes conjuguées, mais c’est tout. Je m’interdis de le lancer si la page de l’infinitif n’est pas créée. Lmaltier (discussion) 10 septembre 2018 à 17:44 (UTC)
- @Romainbehar, ben oui, comme le dit Lmaltier, le bot ne va pas créer la définition à ta place ! (les IA font des progrès, mais pas à ce point-là) --Ars’ 10 septembre 2018 à 18:31 (UTC) (et moi non plus, je ne vais quand même pas faire ton boulot)
- Voilà qui est fait ! Romainbehar (discussion) 10 septembre 2018 à 18:50 (UTC)
- Magnifique
, colosséen, titanesque, pharaonique, herculéen…Je n’aurais pas pu faire aussi bien. Tu vois, on n’est jamais si bien servi que par soi-même. --Ars’ 10 septembre 2018 à 18:57 (UTC)
--Ars’ 10 septembre 2018 à 18:57 (UTC)
- Magnifique
- Voilà qui est fait ! Romainbehar (discussion) 10 septembre 2018 à 18:50 (UTC)
- @Romainbehar, ben oui, comme le dit Lmaltier, le bot ne va pas créer la définition à ta place ! (les IA font des progrès, mais pas à ce point-là) --Ars’ 10 septembre 2018 à 18:31 (UTC) (et moi non plus, je ne vais quand même pas faire ton boulot)
Reform of the English[modifier le wikicode]
(à prononcer Code langue manquant !)
boathouse, houseboat, boatboat, househouse :
Ben, il y en a au moins deux qui nous manquent ! --Ars’ 10 septembre 2018 à 18:47 (UTC)
- Le vocabulaire n’est pas toujours transparent : Why Do We Park in the Driveway and Drive on the Parkway? — TAKASUGI Shinji (d) 10 septembre 2018 à 21:23 (UTC)
Wikiconvention francophone les 5, 6 et 7 octobre à Grenoble[modifier le wikicode]
Comme présenté le mois passé, dans quelques semaines se tiendra la rencontre annuelle des gens intéressés par les projets collaboratifs en ligne. Cette année, on fait le plein de propositions autour du Wiktionnaire !
- Conférence grand public Wiktionnaire : au delà du dictionnaire
- Atelier de formation à la contribution S’amuser dans le Wiktionnaire
- Rencontre autour du Wiktionnaire
- Rencontre autour de la wikipresse (RAW, Wikimag, Actualités du Wiktionnaire, Wikilettre, etc.)
- Rencontre autour des Langues de France - Bilan et perspectives
Conférences courtes :
- Lingua Libre - On l’a fait ! par Lyokoï
- Un MOOC pour Wiktionnaire et les Wiki-Test avec un exemple par Reda Kerbouche
- Wikipédia devrait-elle être encore moins un dictionnaire ? par Lyokoï
- et en cinq minutes je parlerai peut-être de ludifier la contribution au Wiktionnaire
Alors alors, qui est inscrit et prévois de s’y rendre ? Pour l’instant, la conférence grand public n’est pas dans le programme et pour l’atelier, on prévoit qu’il y ait Lyokoï, Ltrlg, DaraDaraDara et moi-même. Si vous prévoyez de venir, n’hésitez pas à nous dire, nous serions très heureux de vous offrir la possibilité de co-animer avec nous l’atelier ! Si vous avez des choses à dire sur ces sujets, vos avis sont les bienvenus. D’ailleurs, DaraDaraDara présentera également quelque chose sur les spécificités de la contribution à Wikisource et elle vous invite à participer à la réflexion en amont de sa présentation !
Ah oui, je profite de parler de rencontres pour vous rappeler que si vous passez à Lyon un premier jeudi du mois, c’est à dire le 4 octobre, 1e novembre, 6 décembre, 3 janvier, 7 février, 7 mars, 4 avril, 2 mai, 6 juin ou 4 juillet vous serez très bien accueillis aux rencontres mensuelles des wiktionnaristes lyonnais et alentours, où nous sommes entre huit et dix personnes à chaque fois. Ce sont de très belles opportunités pour faire avancer nos projets et pour voir comment les autres contribuent, et puis bon, on est sympa ![]() Noé 11 septembre 2018 à 14:47 (UTC)
Noé 11 septembre 2018 à 14:47 (UTC)
- Ouais, y'a de la bière et c'est super cool et très sympa. --109.213.96.140 11 septembre 2018 à 18:57 (UTC)
Mauvaises définitions de flexions de noms et d'adjectifs[modifier le wikicode]
Nous avons encore beaucoup de pages de flexions créées par PiedBot avec des définition commençant par un Masculin ou un Féminin injustifié. Par exemple noisetiers : Masculin pluriel de noisetier, ou encore impropres : Féminin pluriel de impropre. J’ai corrigé récemment ces deux exemples, mais il en reste certainement des quantités. Est-ce qu’un robot pourrait en faire une liste des flexions de noms commençant par Masculin ou par Féminin, et de même pour les flexions d’adjectifs marqués dans la page du singulier comme identiques au masculin et au féminin ? Si cette liste existe déjà, où est-elle ? Lmaltier (discussion) 12 septembre 2018 à 18:01 (UTC)
- Ce n'est pas impossible, mais il y avait des cas comme fofolles ou le bot ne pouvait retrouver le singulier ("fofolle") qu'en interprétant magiquement la page "foufou" (car le nom masculin n'a pas d'équivalent féminin mentionné à cette heure). JackPotte ($♠) 12 septembre 2018 à 19:08 (UTC)
- Pour les noms communs, c’est facile, le robot n’a pas à interpréter pour signaler le problème : une forme de nom commun qui commence par Masculin pluriel ou Féminin pluriel ou Masculin singulier ou Féminin singulier, c’est une erreur, dans tous les cas. Je pense préférable de ne pas faire de correction automatique, sauf si on se met d’accord après discussion sur une méthode sans risque d’erreur. Lmaltier (discussion) 12 septembre 2018 à 19:55 (UTC)
Niveau de section des notes[modifier le wikicode]
Bonjour, depuis 2005 les sections "note" et "notes" ont un titre de niveau HTML 5 (puisque 5 égals en wikicode sont rendus <h5> dans le code source de la page). Et même si depuis 2013 chacun peut personnaliser les siens avec le modèle "S" en Lua, leur niveau n'avait jamais été remis en cause, donc mon bot réappliquait bêtement le 5.
Or, la plupart de nos notes étant placées dans des natures (niveau 3), leurs notes devraient être de niveau 4. Puisque comme le fait remarquer Hégésippe Cormier (d · c · b), authors should use headings that are properly nested (e.g., h1 followed by h2, h2 followed by h2 or h3, h3 followed by h3 or h4, etc.).[1]. Sinon cela peut flinguer le rendu dans les navigateurs voire le référencement des moteurs de recherche. Je propose donc de mettre à jour nos pages d'aide et mon bot avec cette norme.
Par ailleurs, le fait d'avoir deux sections "note" et "notes" complique inutilement notre syntaxe car c'est la seule section dont le nom dépend de la taille de son contenu. Qui peut comprendre intuitivement qu'il faut lui ajouter un "-s" quand on ajoute une deuxième note ? Je propose donc d'uniformiser vers le pluriel, comme on le fait pour les titres 4 (synonymes, dérivés, etc.) même quand ils ne contiennent qu'une seule entrée. "note" pouvant être un alias "notes", cela ne perturbera pas les anciens éditeurs. JackPotte ($♠) 15 septembre 2018 à 08:28 (UTC)
- Pour que notes soit de niveau 4 ou 5 et toujours au pluriel Noé 15 septembre 2018 à 08:44 (UTC)
- La section Notes peut en effet dépendre de différentes sections, pas seulement de sections de niveau 3, il faut donc laisser un niveau libre comme c’est le cas actuellement (même si la plupart du temps, c’est le niveau 4 qui correspond). — Automatik (discussion) 18 septembre 2018 à 10:22 (UTC)
- Même Pour que Noé. --— Lyokoï (Discutons ) 18 septembre 2018 à 18:55 (UTC)
Mise en place de glossaires[modifier le wikicode]
Salut tout le monde,
Il ne me semble pas que nous ayons pour le moment de glossaires, avec un espèce de nom dédié comme pour les thésaurus par exemple.
Cela me semblerait pourtant pertinent de créer un tel espace, qui viendrait compléter le besoin de page synthétisant les définitions pertinentes pour un domaine précis, là où le thésaurus ne regroupe bien des termes par thématiques sans les définir et où l’espace de nom principale définie les termes de façon transverse à toute thématique.
Qu’en dites-vous ? --Psychoslave (discussion) 17 septembre 2018 à 11:52 (UTC)
- Ne serait-ce pas déjà le rôle tenu par les lexiques ? Noé 17 septembre 2018 à 11:55 (UTC)
- Je dirais que non, dans la mesure où le glossaire devrait être un document unique où figure et les termes et les définitions pertinentes. --Psychoslave (discussion) 17 septembre 2018 à 14:35 (UTC)
- Un peu comme les pages de la w:Catégorie:Lexique et interwikis. c’est ça ? Otourly (discussion) 17 septembre 2018 à 14:45 (UTC)
- Je dirais que non, dans la mesure où le glossaire devrait être un document unique où figure et les termes et les définitions pertinentes. --Psychoslave (discussion) 17 septembre 2018 à 14:35 (UTC)
Il me semble que ça ferait double emploi, quand même. Les catégories de lexiques sont utilisables pour ça, il suffit de cliquer sur les mots. Et si on veut une organisation, on utilise les pages de thésaurus. L’idée du projet est de faire une page par mot, la proposition reviendrait à revenir à une approche traditionnelle, celle des dictionnaires papier (ou plutôt des glossaires papier), c’est donc un peu incohérent avec l’esprit du projet. Lmaltier (discussion) 17 septembre 2018 à 17:39 (UTC)
- Cette demande a pourtant été formulée par le passé à plusieurs reprises : Wiktionnaire:Wikidémie/avril 2009#Version PDF, Wiktionnaire:Wikidémie/octobre 2016#Listes personnelles de mots. Note : Spécial:Livre qui permet entre autres de combiner des articles d’une même catégorie en un PDF, est en cours de mise à jour. Mais pour faire des glossaires, il faudrait de toute façon un outil à part, capable de parser le Wiktionnaire pour n’en retirer que les définitions d’un domaine en particulier. Je sais que Dakdada a un parseur, qui pourrait éventuellement servir de base pour le développement d’un tel outil… — Automatik (discussion) 17 septembre 2018 à 17:53 (UTC)
- Effectivement, c’est une possibilité pour produire des glossaires (à imprimer sur papier ou à conserver dans des fichiers). Je n’avais pas compris du tout ça dans cette proposition. Lmaltier (discussion) 17 septembre 2018 à 19:26 (UTC)
Quand je parle d'un glossaire, je ne pense pas nécessairement à un format pdf. Bien sûr une version adapté pour l'impression pour ceux qui en souhaite une c’est encore mieux. Ce que j'appelle ici un glossaire, c'est comme par exemple celui de Méta : un terme un ensemble de définitions pertinentes pour le contexte du glossaire. C’est très différent du fait de naviguer à travers des catégories et de chercher les définitions pertinentes pour le contexte visé.
Je pense que la discussion peut être séparé en deux points bien distincts:
- la proposition de créer un espace de nom Glossaire:
- comment les articles de cette espace, s'il est accepté, sont structurés et peuplés.
Donc avant de discuter du second point, je pense que nous devrions nous accorder sur la pertinence du premier point. Si cela paraît suffisamment pertinent, je lancerai une demande de prise de décision plus formel. Par avance merci pour vos retours. --Psychoslave (discussion) 18 septembre 2018 à 09:45 (UTC)
- Pas très fan de l’ajout d’un nouvel espace de nom. Par contre, je pense que c’est très pertinent un outil qui permet de générer un glossaire à partir d'une catégorie en ne listant que les définitions correspondant à la catégorie. --— Lyokoï (Discutons ) 18 septembre 2018 à 10:10 (UTC)
- Notons qu’il existe déjà des glossaires ici, comme Annexe:Glossaire du parler gaga ou Annexe:Lexique de techniques culinaires (voir d’autres glossaires). Cela dit, multiplier les glossaires risque de dupliquer du contenu des pages (certes sous un format intéressant, mais peut-être qu'un outil automatisé serait plus adapté pour cela). — Automatik (discussion) 18 septembre 2018 à 10:17 (UTC)
- Ok pour l’outil qui génère des glossaires à partir de l'existant. En l’état actuel le plus simple serait effectivement de faire mouliner un bot comme tu l’indiques. Par contre je ne sais pas si les définitions correspondantes seront systématiquement annoté par la catégorie, je suis preneur de retours sur ce point. Ensuite une fois ces documents automatiquement créés, où publiera-t-on ce que l'automate générera ?
- Cela interroge également l’évolution du résultat, ce qui dépend aussi de où on le publie. Si c'est publié dans une page wiki non protégé, cela ouvre à la possibilité d'une évolution parallèle, sinon il serait bon de toujours avoir un pointeur permettant de facilement modifier la page qu’il faut éditer pour faire évoluer le glossaire, notamment pour y ajouter un terme non présent et ajouter/modifier une définition.
- Pour une évolution automatique directement depuis le wiki, ça me paraît difficile : bien qu’une extraction depuis un article via un module Lua ne me paraît pas complétement techniquement impossible, c'est surtout la limite de temps de calcul qui me paraît la contrainte la plus susceptible de rendre cela non-fonctionnel. --Psychoslave (discussion) 18 septembre 2018 à 12:39 (UTC)
- Et une intégration à la Wikisource ? Otourly (discussion) 18 septembre 2018 à 12:43 (UTC)
- C’est à dire une intégration à la Wikisource ? --Psychoslave (discussion) 18 septembre 2018 à 13:20 (UTC)
- Comme avec les balises <pages index="XXXXX.djvu" header=1 from=25 to=79 /> que l'on peut trouver dans les livres sur Wikisource. Je crois que le terme exact est une transclusion. Otourly (discussion) 18 septembre 2018 à 13:30 (UTC)
- Pourquoi Wikisource ? Ce serait plutôt Wikilivres, où l’on peut trouver du matériel pédagogique. Mais des listes pourraient trouver leurs places sur le Wiktionnaire. D’ailleurs, j’avais fait une proposition qui allait dans le même sens ses dernières années, lors de la consultation technique de 2017 et lors de la consultation technique de 2018, puis j’avais créé un ticket, T183108 Noé 18 septembre 2018 à 15:18 (UTC)
- @Noé : ma remarque n’était pas à propos d’un lieu d’hébergement mais sur la façon de faire. En effet, Wikisource transclut des éléments de page pour séparer les différentes parties des livres de manière à s’affranchir les limites du papier. Sur le Wiktionnaire, on pourrait transclure les définitions souhaitées dans une page de lexique/glossaire. Otourly (discussion) 18 septembre 2018 à 20:35 (UTC)
- Pourquoi Wikisource ? Ce serait plutôt Wikilivres, où l’on peut trouver du matériel pédagogique. Mais des listes pourraient trouver leurs places sur le Wiktionnaire. D’ailleurs, j’avais fait une proposition qui allait dans le même sens ses dernières années, lors de la consultation technique de 2017 et lors de la consultation technique de 2018, puis j’avais créé un ticket, T183108
- Comme avec les balises <pages index="XXXXX.djvu" header=1 from=25 to=79 /> que l'on peut trouver dans les livres sur Wikisource. Je crois que le terme exact est une transclusion. Otourly (discussion) 18 septembre 2018 à 13:30 (UTC)
- C’est à dire une intégration à la Wikisource ? --Psychoslave (discussion) 18 septembre 2018 à 13:20 (UTC)
- Et une intégration à la Wikisource ? Otourly (discussion) 18 septembre 2018 à 12:43 (UTC)
Sinon j'ai regardé, du côté des modules Lua, lister les catégories, c'est mort. Je vais voir si je trouve d’autres pistes, mais dans tout les cas on est dans un cas qui arrive dans les limites de ce qu'il est possible de faire en l’état de la plateforme et de la manière dont on stocke les données. --Psychoslave (discussion) 18 septembre 2018 à 13:20 (UTC)
Par contre, ce qu'il est possible de faire avec Extension:Labeled Section Transclusion c'est de marquer les passages qu'il est possible d'extraire de façon explicite dans le wikicode. À mon avis, c'est pas génial comme perspective, ça obligerait à rajouter des balises à foison. --Psychoslave (discussion) 20 septembre 2018 à 03:03 (UTC)
Statistiques de l'outil d'ajout de traductions[modifier le wikicode]
Pour les curieux, quelques stats sur l’assistant d’ajout de traductions depuis son lancement en juillet 2014 au 1er septembre 2018 :
- Au total, le nombre de traductions ajoutées avec l’assistant s’élève à : 234 989
- en date du 1/09/2018, le Wiktionnaire contenait environ 861 855 traductions[Note 1] — voir Wiktionnaire:Statistiques-trad pour des stats plus poussées sur les traductions dans le projet
- 45 428 pages ont été modifiées avec Translation editor (hors pages avec uniquement des ajouts révoqués)
Les traductions ajoutées se répartissent ainsi :
- 168 122 traductions ont été ajoutées par des utilisateurs inscrits,
- et 66 867 l’ont été par des utilisateurs non inscrits.
Sur les 143 844 ajouts réalisés avec l’assistant, 4502 ajouts ont été révoqués, parmi lesquels :
- 1 060 ajouts de contributeurs inscrits,
- 3 442 ajouts d'IPs.
Ajouts par langue (via l’outil)[modifier le wikicode]
Voir plus dans MediaWiki:Gadget-translation editor.js/Statistiques…
Note[modifier le wikicode]
- ↑ Ce chiffre est une estimation hausse (plus d’infos).
— Automatik (discussion) 17 septembre 2018 à 17:23 (UTC)
- Woh, super ! C’est chouette de pouvoir connaître ça ! Dis, est-ce que ça te dirais d’en faire un petit article dans les Actualités de ce mois-ci ? En présentant brièvement l’historique du développement du gadget et en donnant ensuite ses bons résultats ? Je pense que ça pourrait être bien d’inscrire cela dans l’histoire du projet Noé 17 septembre 2018 à 18:17 (UTC)
- Et le planning prévisionnel pour la prochaine étape : les suggestions via Google Translation API
 . JackPotte ($♠) 17 septembre 2018 à 19:08 (UTC)
. JackPotte ($♠) 17 septembre 2018 à 19:08 (UTC)
- C’est une idée, mais cela risque d’augmenter le nombre d’utilisateurs ajoutant des traductions dans des langues qu’ils ne maitrisent pas. Actuellement les utilisateurs ajoutent des traductions soit dans des langues qu'ils maitrisent, soit, la plupart du temps, après vérification auprès de sources fiables. Or Google Translate n’est pas une source fiable. Et pour les mots avec plusieurs sens la suggestion serait plus imprécise.
- J’avais plutôt imaginé que ces chiffres puissent servir de base, de motivation pour le développement d’autres éditeurs de ce type (par exemple un éditeur pour les listes de synonymes, dérivés,…, pour les tableaux de flexions, etc.), développement éventuellement soutenu financièrement par Wikimédia. Avis aux amateurs. — Automatik (discussion) 17 septembre 2018 à 20:20 (UTC)
- Et le planning prévisionnel pour la prochaine étape : les suggestions via Google Translation API
- @Noé : c’est fait. Je te laisse voir pour les balises de traduction, je risque fort de me louper. — Automatik (discussion) 17 septembre 2018 à 20:20 (UTC)
Demande d'une instance Wikibase dédiée pour accueillir des définitions des wiktionnaires[modifier le wikicode]
Salut, suite à ma demande concernant les glossaires un peu plus tôt, je me suis un peu repris à cogiter sur les possibilités de mieux coordonner les usages et réusages des données définitionnels et j’ai donc rédigé un ticket faisant une demande d'instance Wikibase pour les wiktionnaires. Je vous laisse le consulter, il est en anglais mais n’hésitez pas à y poser vos questions dans la langue qu’il vous sied, ou de faire des retours ici en français. --Psychoslave (discussion) 18 septembre 2018 à 14:10 (UTC)
- « Instance Wikibase » gagnerait à être explicité. — Automatik (discussion) 18 septembre 2018 à 14:35 (UTC)
- Le texte déposé dans Phabricator n’est pas très clair sur les raisons qui poussent à demander une autre wikibase que Wikidata. S’agit-il d’une wikibase par Wiktionnaire ou d’une seule pour tout Wiktionary ? Pourrais-tu évaluer l’intérêt de ta proposition au regard de Dbnary et GLAWI ? Noé 18 septembre 2018 à 15:37 (UTC)
- Étant donné l’impact d’une telle installation sur les projets, je suis choqué qu'une telle demande n’est pas fait lieu d'une consultation communautaire AVANT… --— Lyokoï (Discutons ) 18 septembre 2018 à 15:47 (UTC)
- Étant donné l’impact d’une telle installation sur les projets, je suis choqué qu'une telle demande n’est pas fait lieu d'une consultation communautaire AVANT… --— Lyokoï (Discutons
- Le texte déposé dans Phabricator n’est pas très clair sur les raisons qui poussent à demander une autre wikibase que Wikidata. S’agit-il d’une wikibase par Wiktionnaire ou d’une seule pour tout Wiktionary ? Pourrais-tu évaluer l’intérêt de ta proposition au regard de Dbnary et GLAWI ?
Merci à Noé pour ses liens. Je comprends la proposition de Psychoslave (une extension parallèle à Wikidata, dédiée aux définitions, avec une licence différente). Mais je ne pense pas que ce serait une bonne chose pour le Wiktionnaire, au contraire : il vaut mieux concentrer les efforts de nos contributeurs ici que disperser cet effort. Je rappelle aussi le principe KISS : tout marche mieux quand on reste aussi simple que possible. Lmaltier (discussion) 18 septembre 2018 à 16:38 (UTC)
- En plus c’est un marteau pour écraser une mouche : comment peut-on imaginer que ça va être accepté simplement pour faciliter l’initiative de production de glossaires par un contributeur isolé ? Cette proposition va sans doute être interprétée comme une simple façon de relancer la question de la licence sur Wikidata. Lmaltier (discussion) 18 septembre 2018 à 17:46 (UTC)
- « Instance Wikibase » gagnerait à être explicité.
- En quel sens ? Wikibase est l'extension de Mediawiki qui permet de gérer les données relationnelles comme le propose Wikidata. Est-ce que c'est cela qu'il faudrait expliciter ? --Psychoslave (discussion) 19 septembre 2018 à 08:32 (UTC)
- Bien sûr ! La plupart des gens qui participent au Wiktionnaire n’ont aucune idée de ce que signifie "données relationnelles", "jeux de données", "peupler une instance", et la plupart n’ont probablement jamais entendu parler de Wikibase. Si tu souhaites t’adresser aux développeurs aussi bien qu’aux communautés susceptibles d’être intéressés par la proposition que tu fais, rédige là en explicitant tous les termes techniques Noé 19 septembre 2018 à 08:49 (UTC)
- Merci, j’avoue que j’ai peut-être trop le nez dans le guidon pour prendre bien la mesure de la technicité des propos que je peux tenir. Donc, pour faire simple, un jeux de données, c'est tout simplement un ensemble de données qui ont un lien quelconque, souvent déterminé par l’usage qui en est fait. L’expression « données relationnelles » indique qu’il s’agit de données dont les relations les unes aux autres sont explicités, tout au moins les relations qui paraissent pertinentes pour un usage ; ce qui permet notamment de faciliter grandement le croisement et le filtrage de ces données en fonction de ces relations. Une instance d’un service logiciel, c’est pour simplifier ce qui résulte du fait de l’exécuter et de permettre son utilisation à une adresse donnée. Par exemple chaque version linguistique de Wikitionnaire repose sur une instance séparée du logiciel Mediawiki. Wikibase est une extension de Mediawiki permettant de saisir des données relationnels. Voilà, je suis preneur de retours des personnes pour qui tout cela n’était pas clair, notamment pour savoir si après explication cela paraît plus clair. --Psychoslave (discussion) 19 septembre 2018 à 09:49 (UTC)
- Bien sûr ! La plupart des gens qui participent au Wiktionnaire n’ont aucune idée de ce que signifie "données relationnelles", "jeux de données", "peupler une instance", et la plupart n’ont probablement jamais entendu parler de Wikibase. Si tu souhaites t’adresser aux développeurs aussi bien qu’aux communautés susceptibles d’être intéressés par la proposition que tu fais, rédige là en explicitant tous les termes techniques
- raisons qui poussent à demander une autre wikibase que Wikidata
- Merci de ce retour, car effectivement pour moi cela paraissait suffisamment explicite et c'est donc d’autant plus important d'avoir ce genre de retour sur mes points aveugles. Les raisons sont :
- mieux partager et coordonner les données entre les différentes versions linguistiques
- apporter plus de souplesse dans la réutilisation des définitions au sein des wikis, permettant de présenter la même définition dans différents contextes et sous différentes formes
- faciliter l’utilisation par des projets externes
- et pourquoi une autre instance de Wikibase, tout simplement parce que Wikidata restera sous CC0 et que, pour ce que j'en sais, nous ne pouvons pas légalement y importer les contenus des wiktionnaires. --Psychoslave (discussion) 19 septembre 2018 à 08:32 (UTC)
- Donc il s’agit bien de solliciter la création d’une alternative à l’espace Lexeme de Wikidata, autant le clarifier. Je serai assez favorable à cela, mais en délimitant clairement les intérêts et limites Noé 19 septembre 2018 à 08:49 (UTC)
- Pas vraiment une alternative, dans la mesure où ce n’est pas le même objet. L’espace Lexeme, tout au moins pour ce que j'ai pu en saisir, est principalement axé sur les paradigmes flexionnels des lexèmes répertoriés, avec pour tout indication sémantique une glose à visé de désambiguïsation. La présente proposition elle est axé sur le matériel définitionnel. Par contre il s’agit effectivement d’un espace bien séparé. Au niveau des limites, je serais pour y inclure l’ensemble des définitions et étymologies groupées par item lexicale, chaque définition pouvant être accompagné d’exemples d'utilisations et des indications telle que les domaine où la définition s’applique, si elle est vieillie, familière, etc. et possiblement des statistiques de fréquence dans des corpus. --Psychoslave (discussion) 19 septembre 2018 à 10:07 (UTC)
- je ne pense pas que ce serait une bonne chose pour le Wiktionnaire, au contraire : il vaut mieux concentrer les efforts de nos contributeurs ici que disperser cet effort
- Ce projet est justement pertinent pour mieux coordonner les efforts et l’évolution des jeux de données, non seulement au sein de chaque version linguistique, mais également entre elles. Je ne sais pas à quoi correspond ce "ici" dans cette phrase, pourrais-je avoir de plus ample explications s’il-te-plaît ? La proposition vise à faire cela « ici même » au sein de l’infrastructure wikimédia. --Psychoslave (discussion) 19 septembre 2018 à 08:22 (UTC)
- Non, ça ne peut rien coordonner entre versions linguistiques, puisque ça ne concerne que des choses écrites dans une langue donnée, et la proposition le précise d’ailleurs bien. Ici, ça veut bien sûr dire notre projet, le Wiktionnaire. Lmaltier (discussion) 19 septembre 2018 à 17:16 (UTC)
- Qu’est-ce qui dans la proposition amène à penser cela exactement ? Car la proposition vise des objectifs fort distinct de ce que je comprends que tu as compris : elle concerne des attestations d’usages[novinst 1] et des définitions qui leurs sont adjointes. Ces matériaux lexicologiques devraient évidemment pouvoir être traduits, voir transcrits quand cela fait sens. --Psychoslave (discussion) 20 septembre 2018 à 01:03 (UTC)
- Bien sûr, tout peut-être traduit, y compris les définitions. Il n’y a pas besoin de mettre les définitions et les attestations dans une base séparée pour qu’elles soient aussi exploitables par les autres versions linguistiques. C’est la logique de Wikidata que je remets en cause, et qui a prouvé sa nocivité avec OmegaWiki. Lmaltier (discussion) 20 septembre 2018 à 05:53 (UTC)
- Certes, ce n’est pas une condition nécessaire de mettre toutes les définitions dans une base relationnelle commune pour échanger des données entre les versions linguistiques. Cela étant, cette proposition ne découle pas d'une recherche visant à déterminer le strict nécessaire pour envisager une situation comme non-impossible. Elle découle d’une volonté de rendre effectif des échanges beaucoup plus fluides et ouvrant à beaucoup de nouvelles possibilités par la facilité du croisement de données qu’elle permet. Il ne s’agit pas de proposer une base séparée, mais une base intégrée à l’environnement wikimédien. Il me semble qu’ici il est important de bien distinguer le compartimentage logiciel des données et la restitution d’une interface d’édition des données. Le présent texte est stocké dans une base de donnée MySQL « séparée », ce qui n’empêche que son édition se fasse via un formulaire HTML « ici ». Je ne connais pas beaucoup OmegaWiki, mais il me semble que l’objectif du projet est assez lointain de la présente proposition. Cette proposition inclut une intégration à l’environnement wikimédien comme un de ses objectifs principals. Il ne semble que ce fut le cas de OmegaWiki qui s’est lancé en dehors de l’infrastructure de Wikimédia. --Psychoslave (discussion) 20 septembre 2018 à 07:30 (UTC)
- Bien sûr, tout peut-être traduit, y compris les définitions. Il n’y a pas besoin de mettre les définitions et les attestations dans une base séparée pour qu’elles soient aussi exploitables par les autres versions linguistiques. C’est la logique de Wikidata que je remets en cause, et qui a prouvé sa nocivité avec OmegaWiki. Lmaltier (discussion) 20 septembre 2018 à 05:53 (UTC)
- Qu’est-ce qui dans la proposition amène à penser cela exactement ? Car la proposition vise des objectifs fort distinct de ce que je comprends que tu as compris : elle concerne des attestations d’usages[novinst 1] et des définitions qui leurs sont adjointes. Ces matériaux lexicologiques devraient évidemment pouvoir être traduits, voir transcrits quand cela fait sens. --Psychoslave (discussion) 20 septembre 2018 à 01:03 (UTC)
- Non, ça ne peut rien coordonner entre versions linguistiques, puisque ça ne concerne que des choses écrites dans une langue donnée, et la proposition le précise d’ailleurs bien. Ici, ça veut bien sûr dire notre projet, le Wiktionnaire. Lmaltier (discussion) 19 septembre 2018 à 17:16 (UTC)
- Je rappelle aussi le principe KISS : tout marche mieux quand on reste aussi simple que possible.
- La complexité, c’est les autres. Outre le détournement humoristique de la sentence sartrienne, il faut bien se rendre compte que la simplicité comme toute chose dépend du point de vu où l’on se place. Les structures en wikicode sont peut-être simple sur quelques plans, mais elles complexifient énormément la réutilisation aussi bien au sein du projet qu'en dehors, elle complexifie la coordination des contributeurs entre les versions linguistiques, et elle complexifie la création d’interfaces plus conviviales, ce qui maintien un niveau de complexité important au niveau de la prise en main des connaissances nécessaires pour contribuer. Donc c’est bien dans un souci de simplification qu’il s’agit de porter ce projet. --Psychoslave (discussion) 19 septembre 2018 à 08:22 (UTC)
- Même réponse que ci-dessus. Et je ne parle que de l’amélioration et de l’enrichissement du projet. C’est fait par des contributeurs humains, ne l’oublions pas. Nous avons déjà peu de contributeurs parce que c’est trop compliqué, il ne faut pas compliquer encore plus. Même un projet qui semblerait idéal sur le plan des principes, de la réutilisation à l’extérieur, etc. ne peut pas fonctionner si les contributeurs disparaissent. J’ai fait une seule contribution à Wikivoyage, il y a de quoi dégoûter tout contributeur normal, La page n’est quasiment formé que de modèles… Si le nombre de contributeurs à Wikipédia a tendance à baisser, c’est pour moi parce que les choses sont devenues plus complexes, et que ça ne plaît qu’à certaines personnes bien précises. Il faut conjuguer simplicité de contribution humaine et robots externes pour récupérer selon les besoins, pour aider à réutiliser entre versions linguistiques, etc. C’est ça l’avenir. Lmaltier (discussion) 19 septembre 2018 à 17:16 (UTC)
- Je partage tout à fait ton souhait d’aller vers une plus grande facilité de contribution. C’est d’ailleurs déjà explicité dans le ticket, une telle démarche vise justement entre autre à faciliter la création d'interfaces plus ergonomiques et plus faciles à prendre en main, aussi bien au sein des Wikis que via des outils externes, par exemple des interfaces spécifiques sous forme de service toolforge. --Psychoslave (discussion) 20 septembre 2018 à 01:10 (UTC)
- Se concentrer sur un seule projet, une seule base, c’est quand même beaucoup plus simple du point de vue contribution, tout contributeur étant libre d’écrire des robots pour se faciliter la vie, ce qui ne complique rien pour les autres contributeurs. Il y a aussi l’aspect psychologique : si on se sent dépossédé de son projet, c’est très démotivant. On le voit sur Wikipédia, où beaucoup détestent Wikidata. Lmaltier (discussion) 20 septembre 2018 à 05:53 (UTC)
- "Se concentrer sur un seule projet, une seule base, c’est quand même beaucoup plus simple du point de vue contribution", oui, je suis tout à fait d’accord, mais comment mettre les définitions dans une base commune pourrait-il aller autrement qu’en ce sens ? La création de robots reste possible, bien que souvent cette étape n'est pas nécessaire pour interagir avec une base de donnée relationnelle où les les mécanismes de requêtes offrent déjà une très large gamme de possibilité qu’il n’est pas possible d’atteindre sans bot lorsqu’on utilise que du wikicode.
- "Il y a aussi l’aspect psychologique : si on se sent dépossédé de son projet, c’est très démotivant.", c'est effectivement alarmant de voir ce type de perspectives s’imposer à l’esprit des contributeurs. Aussi je souhaiterais comprendre qu’est-ce qui peut bien inspirer une telle frayeur dans la proposition faite. La proposition ne vise pas à déposséder la communauté de son projet, mais à lui offrir de puissants outils en plus de ce dont elle bénéficie déjà, qu’elle est libre d’utiliser ou non à son grès. Mis à part par amalgame avec le déficit de réputation de Wikidata que tu évoques, en quoi la proposition d’une instance de Wikibase visant à offrir plus de services utilisables par les Wiktionnaires constitue un dépossession ? --Psychoslave (discussion) 20 septembre 2018 à 07:52 (UTC)
- Se concentrer sur un seule projet, une seule base, c’est quand même beaucoup plus simple du point de vue contribution, tout contributeur étant libre d’écrire des robots pour se faciliter la vie, ce qui ne complique rien pour les autres contributeurs. Il y a aussi l’aspect psychologique : si on se sent dépossédé de son projet, c’est très démotivant. On le voit sur Wikipédia, où beaucoup détestent Wikidata. Lmaltier (discussion) 20 septembre 2018 à 05:53 (UTC)
- Je partage tout à fait ton souhait d’aller vers une plus grande facilité de contribution. C’est d’ailleurs déjà explicité dans le ticket, une telle démarche vise justement entre autre à faciliter la création d'interfaces plus ergonomiques et plus faciles à prendre en main, aussi bien au sein des Wikis que via des outils externes, par exemple des interfaces spécifiques sous forme de service toolforge. --Psychoslave (discussion) 20 septembre 2018 à 01:10 (UTC)
- Même réponse que ci-dessus. Et je ne parle que de l’amélioration et de l’enrichissement du projet. C’est fait par des contributeurs humains, ne l’oublions pas. Nous avons déjà peu de contributeurs parce que c’est trop compliqué, il ne faut pas compliquer encore plus. Même un projet qui semblerait idéal sur le plan des principes, de la réutilisation à l’extérieur, etc. ne peut pas fonctionner si les contributeurs disparaissent. J’ai fait une seule contribution à Wikivoyage, il y a de quoi dégoûter tout contributeur normal, La page n’est quasiment formé que de modèles… Si le nombre de contributeurs à Wikipédia a tendance à baisser, c’est pour moi parce que les choses sont devenues plus complexes, et que ça ne plaît qu’à certaines personnes bien précises. Il faut conjuguer simplicité de contribution humaine et robots externes pour récupérer selon les besoins, pour aider à réutiliser entre versions linguistiques, etc. C’est ça l’avenir. Lmaltier (discussion) 19 septembre 2018 à 17:16 (UTC)
- S’agit-il d’une wikibase par Wiktionnaire ou d’une seule pour tout Wiktionary ?
- L’idée concerne bien une unique instance de Wikibase, accessible depuis l’ensemble des projets Wikimédia (au moins à terme). --Psychoslave (discussion) 19 septembre 2018 à 08:22 (UTC)
- Clairement un concurrent des données lexicographiques de Wikidata donc Noé 19 septembre 2018 à 08:49 (UTC)
- En ma connaissance actuel du projet des données lexicographiques de Wikidata, le type de données explicitement visés n’est pas le même. Avec Lexeme l’accent est mis sur les paradigmes de mots, ici il s’agit de mettre l’accent sur des relations entre des attestations et des définitions. --Psychoslave (discussion) 19 septembre 2018 à 10:20 (UTC)
- Je pense ce que nous ayons besoin de partager entre Wiktionnaire sont les règles d’accord, de déclinaison ou de conjuugaison. Ensuite on pourrait avoir besoin de Wikibase pour ajouter des cartes dynamiques. Le reste risque d’être un poids lourd à porter pour la communauté au-delà des réticences. Bref s’il faut commencer par quelque chose, commençons par les besoins et peut-être que d’autres besoins apparaîtront par la suite. Un escalier de 10 marches est difficile à gravir en une enjambée, mais marche après marche on peut y arriver. Bien sûr tout doit être fait avec l’accord de la communauté. Otourly (discussion) 20 septembre 2018 à 04:40 (UTC)
- Je suis d’accord que partager les règles d’accord serait également intéressant, c'est un point qui diffère cependant complétement de la proposition. La solution qui me vient à l’esprit pour cela nécessiterait la possibilité de faire des appels interwiki à des modules Scribunto implémentant ces règles, et cela n’est actuellement pas techniquement directement possible, voir Scribunto should support global module invocations. Par contre ce qui est suggéré dans le ticket, c'est de créer des modules Scribunto et de les embarquer dans une extension Mediawiki pour qu’ils soient déployés dans l’ensemble des Wiktionnaires. En l’occurrence ici les barrières techniques de réalisation et de déploiement sont vraiment beaucoup plus simple. Nous pouvons déjà effectivement lancer ça. Si ça vous intéresse, je peux créer le ticket phabricator.
- Cette idée avait fait l'objet, contrairement à ta proposition, des projets soumis à la WMF donc oui c'est un point intéressant. Reste à savoir comment mettre ça en application. Otourly (discussion) 20 septembre 2018 à 13:18 (UTC)
- Pour les cartes dynamiques, oui ça peut être intéressant, mais ce n'est pas l’objet de la proposition en question. Éventuellement, on pourrait ajouter ce type d’informations ultérieurement dans l’instance en question, ou encore dans une autre instance de Wikibase. En l’occurence, les articles du Wiktionnaire ne comprennent pour le moment aucune données sur la répartition géographique des termes. Aussi il me parait plus aisé de commencer par importer ce que nous avons déjà, des définitions, avec des besoins déjà explicité de facilitation de réutilisation multiple d’une même définition. Pour reprendre ton analogie, il me semble que ce serait bien là une première marche, là où les données cartographiques correspondrait à vouloir gravir une marche pour laquelle nous n’avons même pas encore le matériel nécessaire pour sa construction. --Psychoslave (discussion) 20 septembre 2018 à 08:12 (UTC)
- Mettre des définitions dans une wikibase ça ressemble à transférer le Wiktionnaire dans une base de donnée. Je pense qu'il y aura peu de contributeurs prêts à passer leur énergie là-dedans. La forme actuelle est souple et permettant des liens internes au sein des définitions. Ta proposition n'est pas simple à mettre en œuvre. C'est pour ça que je pense que si le Wiktionnaire doit (et le doit-il vraiment ?) se rapprocher d'une base de donnée, il faut y aller doucement, et par des idées qui font déjà sens au sein de la communauté. Et là encore le partage des règles d'accord, de déclinaison et de conjugaison ne font pas l'unanimité. Otourly (discussion) 20 septembre 2018 à 13:18 (UTC)
- Je suis d’accord que partager les règles d’accord serait également intéressant, c'est un point qui diffère cependant complétement de la proposition. La solution qui me vient à l’esprit pour cela nécessiterait la possibilité de faire des appels interwiki à des modules Scribunto implémentant ces règles, et cela n’est actuellement pas techniquement directement possible, voir Scribunto should support global module invocations. Par contre ce qui est suggéré dans le ticket, c'est de créer des modules Scribunto et de les embarquer dans une extension Mediawiki pour qu’ils soient déployés dans l’ensemble des Wiktionnaires. En l’occurrence ici les barrières techniques de réalisation et de déploiement sont vraiment beaucoup plus simple. Nous pouvons déjà effectivement lancer ça. Si ça vous intéresse, je peux créer le ticket phabricator.
- Je pense ce que nous ayons besoin de partager entre Wiktionnaire sont les règles d’accord, de déclinaison ou de conjuugaison. Ensuite on pourrait avoir besoin de Wikibase pour ajouter des cartes dynamiques. Le reste risque d’être un poids lourd à porter pour la communauté au-delà des réticences. Bref s’il faut commencer par quelque chose, commençons par les besoins et peut-être que d’autres besoins apparaîtront par la suite. Un escalier de 10 marches est difficile à gravir en une enjambée, mais marche après marche on peut y arriver. Bien sûr tout doit être fait avec l’accord de la communauté. Otourly (discussion) 20 septembre 2018 à 04:40 (UTC)
- En ma connaissance actuel du projet des données lexicographiques de Wikidata, le type de données explicitement visés n’est pas le même. Avec Lexeme l’accent est mis sur les paradigmes de mots, ici il s’agit de mettre l’accent sur des relations entre des attestations et des définitions. --Psychoslave (discussion) 19 septembre 2018 à 10:20 (UTC)
- Clairement un concurrent des données lexicographiques de Wikidata donc
- Pourrais-tu évaluer l’intérêt de ta proposition au regard de Dbnary et GLAWI ?
- Oui, avec plaisir. Je ne connaissais pas ces projets, donc déjà, merci. Ces projets sont intéressants et pourraient même être utiles pour peupler l’instance Wikibase en question. Cependant ils ne permettent pas de faire de requêtes depuis l’ensemble des projets Wikimédia, comme c’est le cas pour les données stockées dans Wikidata. Sur ce plan, ces projets ne sont en l’état pas plus utile que s’il n’existaient pas du tout. --Psychoslave (discussion) 19 septembre 2018 à 08:32 (UTC)
- En plus c’est un marteau pour écraser une mouche
- Ce n'est pas que pour les glossaires, il ne faudrait pas réduire une proposition à un cas d'utilisation donné en exemple. Les champs d’utilisation sont bien sûr ouverts et ne sont limités que par les souhaits d’utilisation ou de non utilisation du service.
- comment peut-on imaginer que ça va être accepté simplement pour faciliter l’initiative de production de glossaires par un contributeur isolé ?
- Évidemment, il est toujours possible de peindre des tableaux noirs et défaitistes qui réduisent toute initiative à une lubie individuelle déconnectée de toute pertinence communautaire. À une question commençant par « peut-on imaginer… », je répondrai « oui certainement, le simple fait d'être à même de le décrire prouve que nous pouvons l’imaginer ». Est-ce que cela adviendra ? Il n’y a qu’en essayant qu’il sera possible de s’en assurer. --Psychoslave (discussion) 19 septembre 2018 à 08:22 (UTC)
- Cette proposition va sans doute être interprétée comme une simple façon de relancer la question de la licence sur Wikidata. Lmaltier (discussion) 18 septembre 2018 à 17
- 46 (UTC)
- Le sujet de la licence n’est certes pas pour rien dans la demande. Pour ma part garder une unique instance avec une espace de nom pour les définitions qui permette un import légal des définitions me conviendrait tout aussi bien. Cela étant, les échanges de ces derniers mois ont bien montré qu'il y avait une volonté ferme et inflexible d’associer Wikidata à l’unique licence CC0. Donc, justement pour éviter de perdre du temps à proposer quelque chose qui n'a vraisemblablement aucune chance d’aboutir positivement, il semble plus judicieux de proposer la création d’une instance séparée, qui est là pour répondre à des besoins qui émanent de la communauté et qui ne peuvent être résolus par Wikidata du fait de sa politique de licence. --Psychoslave (discussion) 19 septembre 2018 à 08:32 (UTC)
- Étant donné l’impact d’une telle installation sur les projets,
- Je serais aussi intéressé de connaître les impacts supposés que chacun peut se figurer pour les projets. En l’état de la proposition, ma perspective de l’impact sera au pire nul si la communauté ne souhaite pas s’emparer du service, si tant est qu'il fut jamais mis en place, et au mieux rendra le Wiktionnaire beaucoup plus souple dans ses usages et beaucoup plus simple à enrichir pour les nouveaux venus tout en offrant des possibilités de partage inter-wiki d'une facilité sans commune mesure avec ce que nous avons aujourd'hui. --Psychoslave (discussion) 19 septembre 2018 à 08:22 (UTC)
- Un impact évident serait le balisage des données ou son fractionnement. Actuellement, le contenu est sur une unique page et la mise en forme est fractionnée (à l’aide de modèle). Séparer les définitions pour les mettre dans une base de donnée implique qu’elles ne soient plus stockées en dur dans une seule et même place. C’est un impact conséquent Noé 19 septembre 2018 à 08:49 (UTC)
- Je ne suis pas sûr de bien comprendre ce qui entendu par « les mettre dans une base de donnée implique qu’elles ne soient plus stockées en dur dans une seule et même place ». Tel que je le conçois, utiliser ce genre de service permet justement de « stocker en dur en une seule et même place ». Concrètement, pour reprendre l’exemple du glossaire, en l’état actuel du Wiktionnaire la solution la plus simple pour créer un glossaire, c'est de dupliquer les données correspondantes, avec une assurance assez forte de voir des évolutions divergentes apparaître rapidement. Avec un service coordonnée et requêtable comme Wikibase, ça permet de réutiliser la même unique définition à plusieurs endroits. Cela dit, il faut aussi voir que même en mettant toutes les définitions actuellement présentes dans les wiktionnaires dans une telle base de donnée, ça ne va pas pour autant impliquer que les données du service seront effectivement utilisés par les wiktionnaires, et si ça n'est pas le cas la problématiques d’évolutions divergentes non-coordonnées resterait importante. Cela étant, même dans le cas d’une absence totale d’intérêt des wiktionnaristes, il me semble que ça garderait un intérêt certain, au même titre qu’Anagrimes ou des projets qui proposent des versions restructurés comme ceux que tu as indiqué. --Psychoslave (discussion) 19 septembre 2018 à 11:15 (UTC)
- Un impact évident serait le balisage des données ou son fractionnement. Actuellement, le contenu est sur une unique page et la mise en forme est fractionnée (à l’aide de modèle). Séparer les définitions pour les mettre dans une base de donnée implique qu’elles ne soient plus stockées en dur dans une seule et même place. C’est un impact conséquent
Une Wikibase pour les textes du Wiktionnaire[modifier le wikicode]
Après réflexion, et après en avoir discuté au téléphone avec Psychoslave, il me semble qu’il pourrait être intéressant d’avoir une Wikibase sous CC BY-SA contenant ce qui est protégé par le droit d’auteur (ou par le copyright ou les droits des bases de données, ou autre selon les coins du monde). Je me souviens de la note légale sur les données lexicographiques publiée en février. Certains ajouts fait dans le Wiktionnaire sont protégés par la licence CC BY-SA, mais pas tous, car certaines informations sont des données qui ne peuvent pas être protégées. Wikidata, qui est sous licence CC0 (similaire à domaine public) ne peut donc pas reprendre une bonne partie des informations contenues dans le Wiktionnaire. Celles-ci ne bénéficieront pas de structuration avancée, et ne pourront pas être exploitées par des machines. Et c’est bien dommage.
Je suis persuadé que de nombreuses personnes extérieures seraient intéressées pour reprendre les définitions joliment rédigées, les exemples bien choisis et les étymologies développées qui peuplent les pages des Wiktionnaires. Tout cela ne sera jamais dans Wikidata. Mais ça pourrait être dans une autre Wikibase, mise à jour régulièrement de manière automatisée, pour permettre un réemploi par d’autres des données plus aisé. Comme je le vois, ça serait juste une conversion des dumps (les copies archivées deux fois par mois) sous une forme davantage balisée. Pour cela, il faudrait écrire des scripts qui puissent convertir les dump Wiktionnaire pour les faire entrer dans des bases de données, ça serait cool. Un peu comme du XSLT permet de transformer du XML en HTML, nous pourrions avoir un script qui transforme des dumps en données pour Wikibase. Avec actualisation régulière.
Et des scripts de transformation des dumps, existe déjà, notamment pour le français (GLAWI et Anagrimes dans une certaine mesure) et pour douze langues (Dbnary). Au niveau technique, ce qui serait un brin complexe, ça serait le script de conversion allant de chaque Wiktionnaire intéressé (donc peut-être seulement douze dans un premier temps, ou même juste un pour tester) vers cette WikibaseLex.
Ensuite, WikibaseLex ou quelque soit son nom, pourrait être en lecture seule, être seulement à la disposition des gens qui voudraient réexploiter les données plus facilement et faire des requêtes dedans. Mais aussi pour les wiktionnaristes qui pourraient détecter des erreurs ou formuler des requêtes dans les définitions, le genre de choses permises par AWB ou d’autres outils extérieurs comme Anagrimes par exemple. Ce serait un outil de contrôle de nos données efficace, me semble-t-il.
Finalement, moi j’aimerai bien une WikibaseLex pour offrir au monde le contenu du Wiktionnaire dans un format plus facilement exploitable. Un contenu qui ne sera jamais dans Wikidata et qui est celui que nous avons produit, nous, ici. Qu’en dites-vous ? ![]() Noé 20 septembre 2018 à 16:34 (UTC)
Noé 20 septembre 2018 à 16:34 (UTC)
- Expliqué comme ça (alimentation seulement par robot), je n’ai rien contre, je ne vois pas d’inconvénients. Cela va dans le sens de ce que j’expliquais : utilisation de robots, pas de contributeurs humains, qui devraient se concentrer sur les projets par langue. L’important est que ça ne change rien du point de vue des contributeurs. Cette base pourrait même contenir aussi les données grammaticales pour remplacer la partie lexicographique de Wikidata (bien que je sois toujours convaincu que les langues ne se laissent pas enfermer comme ça de la façon dont les promoteurs de Wikidata le supposent). Lmaltier (discussion) 20 septembre 2018 à 16:47 (UTC)
- Comme je l’imagine - et qui est un peu différent de ce que proposait Psychoslave initialement - la WikibaseLex (ou WixBase ?) contiendrait tout ce qui est dans le Wiktionnaire, sauf qu’elle serait une interface de consultation et non une interface de contribution. Cela ne remplacerait pas Wikidata, mais serait complémentaire. Il faudra le répéter plusieurs fois pour réussir à convaincre les promoteurs de Wikidata comme tu dis, car faute d’un Wiktionary product manager, nous sommes dépendant de la Wikidata product manager, qui gère aussi Wikibase. Mais si nous continuons à y réfléchir, et à voir les étapes de développement nécessaires pour la construction du script de conversion, je pense que nous pourrons les convaincre de la faisabilité et de l’utilité d’un tel projet. Et puis, ça montrerait à tout le monde que Wikibase, c’est quand même super pratique, même pour présenter des données Noé 20 septembre 2018 à 17:02 (UTC)
- Comme je l’imagine - et qui est un peu différent de ce que proposait Psychoslave initialement - la WikibaseLex (ou WixBase ?) contiendrait tout ce qui est dans le Wiktionnaire, sauf qu’elle serait une interface de consultation et non une interface de contribution. Cela ne remplacerait pas Wikidata, mais serait complémentaire. Il faudra le répéter plusieurs fois pour réussir à convaincre les promoteurs de Wikidata comme tu dis, car faute d’un Wiktionary product manager, nous sommes dépendant de la Wikidata product manager, qui gère aussi Wikibase. Mais si nous continuons à y réfléchir, et à voir les étapes de développement nécessaires pour la construction du script de conversion, je pense que nous pourrons les convaincre de la faisabilité et de l’utilité d’un tel projet. Et puis, ça montrerait à tout le monde que Wikibase, c’est quand même super pratique, même pour présenter des données
Un grand merci à Noé d’avoir pris le temps de discuter avec moi par téléphone et d’avoir également pris le temps de rédiger une approche différente du projet. Je trouve que la proposition est très bien. Il faudrait encore un tout petit peu que nous spécifions les contours du projets, et les étapes.
Déjà, je ne suis pas sûr que ce soit ce qui est souhaité, mais il me semble que cette approche suppose implicitement qu'il ne sera pas possible pour tout à chacun de modifier directement la Wikibase en question. Seuls les mise-à-jours depuis des extractions des wiktionnaires viendraient modifier cette base, est-ce que c'est bien cela qui est proposé ?
D’un point de vue de la configuration de l’instance, faudrait-il ou non incorporer l’extension Lexeme ? À mon sens, non, l’idée serait plutôt d’utiliser directement la notion d’item de Wikibase pour stocker distinctement les entités de type
- item lexicale
- définition
- exemple d’usage
Pour certaines informations je suis plus partagé sur la manière de les intégrer. L’étymologie pourrait tout aussi bien se placer comme attribut d'un item lexicale que comme entité distinct mis en relation avec l’item. De même pour la transcription API des prononciations que nous n’avions pas encore évoqué explicitement. Vos avis sont les bienvenus. ![]()
Si nous décidons d’importer plusieurs versions linguistiques, comment envisageons nous la fusion d’entrées en correspondance ?
Il y a aussi la question des attributions, comment bien créditer les personnes ayant contribuer aux différents éléments que nous allons importer. Je n’ai pas encore regardé les projets indiqués par Noé en détail pour voir comment ils ont pris cela en compte. Dans le cas d’extraction où toute une page donne une seule entrée, c’est plus simple, puisqu’il suffit de citer l’ensemble des contributeurs de la page. Si nous faisons des extractions à une séparation plus fine:
- nous pouvons viser une attribution d’une égale finesse, ce qui est potentiellement beaucoup plus compliqué ;
- nous pouvons aussi prendre le chemin tout à fait inverse et considérer l’ensemble de la base produite comme un travail dérivé de l’ensemble des auteurs et autrices des wiktionnaires utilisés et créer une unique page de crédit réunissant toutes les attributions ;
- ou nous pouvons également citer pour chaque élément importé l’article source et son historique comme faisant office de page de crédit.
Pour ce qui est des données grammaticales, nous pourront toujours voir ultérieurement, je pense que sans ces données, ça représente déjà un beau chantier en perspective, inutile de trop le charger. De plus, tout au moins pour ce qui est des paradigmes, il peuvent plus opportunément se modéliser dans des modules Scribunto. Les modules ne sont pas encore appelables entre les wikis, mais si nous faisons déjà un effort de coordination sur la création de telles modules, ils peuvent être enrobé dans une extension Mediawiki qui sera installé sur tous les wikis ensuite.
Pour le nom, Wikibaselex me paraît un brin long. Wikilex risquerait de maintenir trop de confusion avec le projet Wikidata/Lexeme. Les autres idées qui me viennent en tête sont Wikisign et Wikivoc (vocable, vocabulaire…). --Psychoslave (discussion) 21 septembre 2018 à 07:53 (UTC)
- Pourquoi vouloir fusionner quoi que ce soit ? Ça mettrait tout par terre. De toute façon, on ne pourra jamais fusionner une définition écrite en français et une définition écrite en japonais… Tous les wiktionnaires importés de cette façon seraient consultables via cette interface, ce qui permettrait des comparaisons éventuelles très intéressantes. Et si ça permet de trouver des incohérences, ce serait très bien, charge à chaque wiktionnaire de corriger le problème éventuel chez lui. Pour la question des attributions pour respecter la licence, ce serait simple : comme ce serait simplement les pages des wiktionnaires accessibles d’une autre façon, il suffirait sans doute de liens vers ces pages. Dans cette approche, on pourrait avoir des bases séparée par langue, mais si c’était dans une seule base, ça ne changerait rien, le wiktionnaire d’origine devant être indiqué dans chaque enregistrement de la base. Lmaltier (discussion) 21 septembre 2018 à 20:26 (UTC)
Sur les logiques de discussions communautaires dans le Wiktionnaire[modifier le wikicode]
- je suis choqué qu'une telle demande n’est pas fait lieu d'une consultation communautaire AVANT… --— Lyokoï
- J’avoue être étonné par le fait que cette demande puisse susciter tant d'émoi. Pour moi la consultation se fait dans le cadre de la demande et évidemment tous les retours constructifs sont les bienvenus, il n’y a rien d’arrêté. Qu'est-ce qu'il n'est pas possible de faire comme retours en l’état qui aurait été possible avec une consultation communautaire sur le droit d'avancer une proposition ? D’ailleurs, où aurait-il fallut conduire à une telle consultation, sur Méta plutôt que phabricator ? C’est une remarque intéressante, mais il me semble qu'elle sort du champ de la demande elle-même et appel plus à une réflexion de fond sur l’équilibre attendu entre « n’hésitez pas » et « prenez en compte l’avis de la communauté ». Il me semble qu'en mettant le ticket sur phabricator et en demandant des retours sur la version anglaise et française du wiktionnaire, je fais déjà une bonne part de la démarche pour stimuler les retours de la communauté, et je suis bien sûr preneur de conseils et de toute proposition d’aide pour mieux communiquer et avoir un retour plus vaste de la communauté. --Psychoslave (discussion) 19 septembre 2018 à 08:22 (UTC)
- Les demandes de ce type sur Phabricator découlent normalement de demandes communautaires et ce n’est pas le cas ici. Tu n’as pas le soutien de la communauté du Wiktionnaire francophone et tu mets, encore une fois, la charrue avant les bœufs Noé 19 septembre 2018 à 08:49 (UTC)
- Il me semble que je ne perçois pas cela de la même manière la communication sur les différents canaux. D’abord je ne ressent pas de différence de nature entre faire des propositions et demander des retours ici, sur phabricator, sur Méta ou d’autres canaux qui je sais fréquenté par des wikimédiens. Bien sûr cela relève de ma propre subjectivité, peut-être que pour d'autres il y a des ressenties de gradation d’importance/officialité/que-sais-je entre un ticket sur phabricator et une discussion sur la Wikidémie. Pour moi la différence majeure c’est le fait qu’à travers phabricator je convie une plus large partie de la communauté à faire ses retours. Je ne souhaite pas limiter les demandes de retours spécifiquement à la sphère francophone. Je vous invite d’ailleurs à faire circuler le mot auprès des autres personnes susceptibles d’être intéressé, quelque soit les langues qu’ils parlent. De même, je ne pense pas que quelqu’un ai besoin d’un soutien communautaire en amont d’une proposition pour pouvoir l’exposer. Bien sûr en aval l’idée peut-être publiquement critiquée et rejetée, sur la base de sa pertinence pour la communauté, quoi de plus sain ? Mais comment obtenir l’aval de la communauté d’exposer une idée avant d’exposer une idée ? Il me semble que quelque chose m’échappe pour éviter l’interprétation d’une injonction impossible à tenir hors le renoncement à toute initiative de proposition. Une telle exigence ne me semble pas en adéquation le fameux « n'hésitez pas » (be bold disent nos amis anglophones). Cela étant, je pense qu’ici il s’agit d’une simple mésinterprétation de ma part, bien que je peine à identifier le nœud de ma méprise. --Psychoslave (discussion) 19 septembre 2018 à 11:41 (UTC)
- Il existe plusieurs communautés qui gravitent autour de celle du Wiktionnaire et qui peuvent avoir des membres en commun. En février, j’avais écris quelques mots sur ce sujet dans les Actualités et je n’avais même pas mentionné Phabricator, car il m’avait semblé qu’il ne s’agissait pas d’une communauté très proche de nous. Nous faisons remonter des bugs de temps en temps mais nous n’avons pas beaucoup de contacts, et ils sont parfois très mauvais. Lorsque nous avons demandé poliment à ce que les deux onglets "Modifier" et "Modifier le wikicode" soient présentés aux IP, il nous avait été répondu que ce n’était pas à nous d’en décider mais à la personne en charge du produit "Éditeur Visuel". Nous nous sommes un peu énervés jusqu’à ce qu'une personne ayant les droits suffisants puisse débloquer la situation. Mais nous n’avons pas sentis être en terrain ami. Nos propositions, qui émanaient des consultations de l’équipe technique, sont restées lettres mortes et j’ai l’impression que nous avons peu de choses à attendre de Phabricator.
- Avoir le soutien des autres avant de demander la création d’un objet qui occupera beaucoup de place sur les serveurs (puisque stockage en double de toutes les données des Wiktionnaires) et qui pourrait modifier grandement la manière dont sont ajoutées des informations dans les pages du Wiktionnaire, ça me paraît plutôt normal. Mais de base, solliciter les autres sur une idée avant de se lancer à la réaliser me paraît toujours souhaitable. Il est très difficile d’évaluer seul les limites et faiblesses d’une idée. Bien l’argumenter avant d’engager du temps et des frais dessus permet de mieux justifier du résultat. Dans toute recherche, il y a des réunions autour des protocoles avant de solliciter l’usage d’une machine ou d’aller sur le terrain. Il en est de même ici, avant d’engager la communauté dans des grands projets, on en discute, on ajoute de nouvelles analyses à une première proposition et on tente de consolider les propositions initiales. Le fameux « n'hésitez pas » n’est pas une injonction à faire n’importe quoi Noé 19 septembre 2018 à 12:22 (UTC)
- Merci @Noé : d'avoir mis cela dans une section séparée et d’avoir pris le temps d’exposer de manière aussi détaillée tes retours. Je vais méditer ça avec attention. --Psychoslave (discussion) 19 septembre 2018 à 12:35 (UTC)
- Merci
- Il me semble que je ne perçois pas cela de la même manière la communication sur les différents canaux. D’abord je ne ressent pas de différence de nature entre faire des propositions et demander des retours ici, sur phabricator, sur Méta ou d’autres canaux qui je sais fréquenté par des wikimédiens. Bien sûr cela relève de ma propre subjectivité, peut-être que pour d'autres il y a des ressenties de gradation d’importance/officialité/que-sais-je entre un ticket sur phabricator et une discussion sur la Wikidémie. Pour moi la différence majeure c’est le fait qu’à travers phabricator je convie une plus large partie de la communauté à faire ses retours. Je ne souhaite pas limiter les demandes de retours spécifiquement à la sphère francophone. Je vous invite d’ailleurs à faire circuler le mot auprès des autres personnes susceptibles d’être intéressé, quelque soit les langues qu’ils parlent. De même, je ne pense pas que quelqu’un ai besoin d’un soutien communautaire en amont d’une proposition pour pouvoir l’exposer. Bien sûr en aval l’idée peut-être publiquement critiquée et rejetée, sur la base de sa pertinence pour la communauté, quoi de plus sain ? Mais comment obtenir l’aval de la communauté d’exposer une idée avant d’exposer une idée ? Il me semble que quelque chose m’échappe pour éviter l’interprétation d’une injonction impossible à tenir hors le renoncement à toute initiative de proposition. Une telle exigence ne me semble pas en adéquation le fameux « n'hésitez pas » (be bold disent nos amis anglophones). Cela étant, je pense qu’ici il s’agit d’une simple mésinterprétation de ma part, bien que je peine à identifier le nœud de ma méprise. --Psychoslave (discussion) 19 septembre 2018 à 11:41 (UTC)
- Les demandes de ce type sur Phabricator découlent normalement de demandes communautaires et ce n’est pas le cas ici. Tu n’as pas le soutien de la communauté du Wiktionnaire francophone et tu mets, encore une fois, la charrue avant les bœufs
Noé m’a également un peu mieux éclairé, il me semble, sur ce point des « communautés qui gravitent autour de celle du Wiktionnaire ». Mon approche s’articule effectivement plus vers un souhait de stimuler au mieux les synergies interprojets réunis dans le mouvement wikimédien. Noé m’a explicité que pour de nombreuses personnes il n’y a pas de sentiment d’appartenance à la communauté wikimédienne ; plus souvent les personnes sont attachés à un projet spécifique et peuvent aller jusqu’à percevoir ceux concentrés autours d’autres projets comme des communautés extérieures, voir possiblement même comme des communautés antagonistes. Pour ma part, je ne prétend pas que je ne perçois aucune situation conflictuelle au sein du mouvement wikimédien, et il me semble qu’il sera difficile de prétendre que je ne met pas parfois les pieds dedans. ![]() Ceci étant, je n’en ressent pas moins un sentiment d’appartenance au mouvement wikimédien, et au-delà à celui de la culture libre, que je perçoit pour ma part comme un tout, non dénué de ses conflits internes et influences externes. Je reste avant tout animé par une volonté de construire des communs. Ce qui, il me semble, ne transparaît malheureusement pas toujours dans mes communications écrites. Par exemple ici il me semble avoir susciter une défiance similaire à ce que je m’attendrait à voir lors de propositions poussés envers et contre tous, alors que mon intention était au contraire d’obtenir des retours permettant de moduler au mieux la proposition pour l’adapter aux attentes variés de la communauté. Je suis d'ailleurs également preneur de toute suggestion pour améliorer mes communications sur ce plan. J’espère que cela rend plus clair ma démarche, dissipera les éventuels craintes qu’elle peut parfois suciter, et je tiens surtout à remercier encore une fois Noé pour son écoute, sa positivité admirable dans l’interprétation des situations, et ses retours constructifs. --Psychoslave (discussion) 21 septembre 2018 à 08:42 (UTC)
Ceci étant, je n’en ressent pas moins un sentiment d’appartenance au mouvement wikimédien, et au-delà à celui de la culture libre, que je perçoit pour ma part comme un tout, non dénué de ses conflits internes et influences externes. Je reste avant tout animé par une volonté de construire des communs. Ce qui, il me semble, ne transparaît malheureusement pas toujours dans mes communications écrites. Par exemple ici il me semble avoir susciter une défiance similaire à ce que je m’attendrait à voir lors de propositions poussés envers et contre tous, alors que mon intention était au contraire d’obtenir des retours permettant de moduler au mieux la proposition pour l’adapter aux attentes variés de la communauté. Je suis d'ailleurs également preneur de toute suggestion pour améliorer mes communications sur ce plan. J’espère que cela rend plus clair ma démarche, dissipera les éventuels craintes qu’elle peut parfois suciter, et je tiens surtout à remercier encore une fois Noé pour son écoute, sa positivité admirable dans l’interprétation des situations, et ses retours constructifs. --Psychoslave (discussion) 21 septembre 2018 à 08:42 (UTC)
- Je ne veux pas paraître rabats-joie, mais lorsque tu fais une proposition, il faut que cela reste une proposition. Créer un ticket phabricator alors que rien n’est décidé dans la communauté, ce n’est pas une proposition. Quand bien même tu l’imagines, cela peut être vécu comme une obligation (du style, j’ai mon idée, elle est forcément bonne, bon je vous la dis, mais voilà, c’est parti), alors c’est forcé qu’on ne suive pas ta démarche ni qu’on te soutienne. À aucun moment avant d’agir, tu ne nous a demandé notre avis et tu n’as non plus jamais vérifié que c’était juste compatible avec notre idée commune (qui est multiple en fait) du fonctionnement du projet.
- En plus, j’ajouterai que tes discussions à base systématique de gros pavés montre aussi que tu ne veux / peux pas prendre le temps de nous résumer l'important de ta décision en filtrant les détails. En esprit critique on peut appeler ça un mille-feuille argumentatif, en gros tu nous noies sous tes idées et tes arguments pour qu'on te suive, or nous sommes justement réfractaires à des discussions longues et sans intérêts (surtout si elles ne prennent pas en compte nos avis, donc qui ne nous concernent pas). --— Lyokoï (Discutons ) 22 septembre 2018 à 22:04 (UTC)
- Coucou ! Encore une fois, encore une fois dans ma perspective faire un ticket phabricator c'était une partie de la démarche pour un appel à commenter et faire évoluer la proposition. Je suis chagriné que cela soit perçu comme une tentative d’imposition agressive, cela n'est pas du tout mon intention. J’ai du mal à percevoir comment ma démarche peut inspirer des sentiments aussi distant de leur objectif, mais j’écoute les remarques qui me sont faites et je médite comment améliorer mes communications. En tout cas, je ne soutient pas les démarches visant à imposer une idée en marche forcée, y compris quand j'en initie la proposition (pour autant je ne réduit pas cela à « mon idée »). Il me semble qu’une proposition initiale aura nécessairement des défauts, qui peuvent en rendre l’idée même caduque, ou qui peut être améliorer au fur et à mesure. Dans ma perspective, je n'ai pas encore commencé à agir : pour moi commencer à agir s’est mettre en œuvre des développement et des déploiements. Du coup de ma perspective, je demande bien d’avoir des avis avant d’agir, ici même et sur phabricator. D’ailleurs, bien que j'ai échoué à le faire transparaître comme tel au départ, c’est bien comme ça que la proposition à déjà commencé à évoluée. J’espère que cela ne sera pas pris comme un « c'est comme ça que tout le monde devrait le percevoir », c’est ma perspective avec ses limites et ses défauts. De la même manière, je ne cherche pas à noyer sous les idées. J’admets que pour moi, synthétiser est difficile. Dans ma perspective, j’aurai plutôt spontanément le sentiment que ce serait se montrer dédaigneux de mes interlocuteurs de ne pas exposer de manière détaillée. J’entends que ce n'est pas en fait perçu comme ça, du coups je demande pardon si j'ai pu involontairement blesser, ou tout au moins offusquer certaines personnes. Contrairement à l’impression que cela semble générer, je me restreint déjà fortement dans le développement de mes propos pour éviter de surcharger mes interlocuteurs. Je vais tenter de m’améliorer encore sur cet aspect de mes communications. Je suis aussi preneur de tout autre conseil pour améliorer mes communications. --Psychoslave (discussion) 24 septembre 2018 à 09:22 (UTC)
Notes[modifier le wikicode]
- ↑ Pas forcément que écrites d'ailleurs, ceci est à mettre en lien avec le fait d'intégrer des vidéos de la langue des signes française dans le Wikitionnaire.
Nouveau Live ce jeudi 20 septembre ! (22h30)[modifier le wikicode]
Bonjour à tous ! Je ferai un nouveau live de contributions sur le Wiktionnaire ce jeudi 20 septembre ! Il portera sur le gaulois (poke Treehill) et me permettra d’expliquer comment contribuer sur les langues mortes. J’espère que vous serez-là pour poser vos questions ! ![]() --— Lyokoï (Discutons
--— Lyokoï (Discutons ![]() ) 18 septembre 2018 à 15:45 (UTC)
) 18 septembre 2018 à 15:45 (UTC)
- @Lyokoï : n'hésite pas à utiliser Spécial:MassMessage avec un hyperlien vers YouTube un quart d'heure avant. Même si cela nécessite de créer une liste de diffusion similaire à Wiktionnaire:Actualités/Inscription. JackPotte ($♠) 18 septembre 2018 à 18:53 (UTC)
- Je crois que créer une liste efficace en deux jours, c’est compliqué (surtout que j'aurais pas forcément le temps, n’en ayant jamais fait auparavant). Mais j’y pense pour la suite, c’est pas con ! --— Lyokoï (Discutons ) 18 septembre 2018 à 19:05 (UTC)
- Bonjour à tous,
Hâte de pouvoir le voir Lyokoï ! Malheureusement je ne pourrai pas le voir en direct cependant :/ Treehill (discussion) 19 septembre 2018 à 04:47 (UTC)
- @Treehill : Ce n’est pas grave, il y aura l’enregistrement, tu pourras le voir quand même ! --— Lyokoï (Discutons ) 19 septembre 2018 à 12:38 (UTC)
- Adresse du live >>>>>> Ici <<<<<<< !! --— Lyokoï (Discutons ) 20 septembre 2018 à 19:22 (UTC)
- Adresse du live >>>>>> Ici <<<<<<< !! --— Lyokoï (Discutons
- Bonjour à tous,
- Je crois que créer une liste efficace en deux jours, c’est compliqué (surtout que j'aurais pas forcément le temps, n’en ayant jamais fait auparavant). Mais j’y pense pour la suite, c’est pas con ! --— Lyokoï (Discutons
Tout est prêt, je vous attends ! ^^ --— Lyokoï (Discutons ![]() ) 20 septembre 2018 à 20:27 (UTC)
) 20 septembre 2018 à 20:27 (UTC)
- Et voici l’enregistrement pour ceux qui n’ont pu être là ! — Lyokoï (Discutons ) 21 septembre 2018 à 12:29 (UTC)
Prononciation de pascuan (et ses formes fléchies)[modifier le wikicode]
Bonjour, je n’ai jamais entendu ce mot donc je ne veux pas « corriger » moi-même mais l’enchainement \kuɑ̃\ me semble louche. Ne serait-ce pas plutôt \kwɑ̃\ ou bien \kɥɑ̃\ (ou encore autre autre chose). Merci d’avance à celui/celle qui regardera ça. Pamputt [Discuter] 18 septembre 2018 à 21:37 (UTC)
- @Pamputt :
 --— Lyokoï (Discutons ) 19 septembre 2018 à 12:26 (UTC)
--— Lyokoï (Discutons ) 19 septembre 2018 à 12:26 (UTC)
- @Lyokoï : Le Grand Robert donne effectivement paskɥɑ̃. Mais, étant donné l’étymologie du mot (il vient du nom en espagnol, pas du nom en français, c’est plutôt inhabituel), je ne peux pas m’empêcher d’avoir un gros doute, de me demander si ce n’est pas une erreur (les erreurs dans les dictionnaires, ça existe…) J’aurais plutôt prononcé paskwɑ̃ . Comme je ne suis pas une référence et que je n’ai jamais l’occasion de prononcer ce mot, je pense que ça vaudrait le coup de vérifier la prononciation effective du mot par les francophones qui ont l’occasion de l’utiliser (par exemple les diplomates français, au Chili, ou les voyageurs qui y sont allés). Lmaltier (discussion) 20 septembre 2018 à 17:14 (UTC)
- Même en m’exerçant je ne suis pas arrivé à prononcer autre chose que pas.ky.ɑ̃ pour pascuan et pascuans ; et pas.ky.an pour pascuane et pascuanes… Alphabeta (discussion) 22 septembre 2018 à 13:37 (UTC)
- L’influence de l’écriture sans doute : je parviens à prononcer kwɑ̃.tɔm pour quantum, sans problème… Alphabeta (discussion) 23 septembre 2018 à 11:50 (UTC)
- J'ai toujours prononcé \kɑ̃tɔm\… — Lyokoï (Discutons ) 23 septembre 2018 à 12:16 (UTC)
- La prononciation kwɑ̃.tɔm correspond la prononciation traditionnelle du latin latin en France de quantum ; qui a pour pluriel quanta kwɑ̃.ta. Alphabeta (discussion) 23 septembre 2018 à 13:39 (UTC)
- J'ai toujours prononcé \kɑ̃tɔm\… — Lyokoï (Discutons
- L’influence de l’écriture sans doute : je parviens à prononcer kwɑ̃.tɔm pour quantum, sans problème… Alphabeta (discussion) 23 septembre 2018 à 11:50 (UTC)
- Même en m’exerçant je ne suis pas arrivé à prononcer autre chose que pas.ky.ɑ̃ pour pascuan et pascuans ; et pas.ky.an pour pascuane et pascuanes… Alphabeta (discussion) 22 septembre 2018 à 13:37 (UTC)
- J’ai consulté sur papier le Grand Dictionnaire Langescheidt français-allemand, Larousse, ISBN 2-03-028102-6 (daté de 1979-1995 par le catalogue de la BNF). On y trouve page 682 une entrée « pascuan », qui indique la prononciation sous la forme « [paskɥɑ̃] ». Alphabeta (discussion) 23 septembre 2018 à 13:39 (UTC)
- J’ai aussi consulté (toujours sur papier) le Grand Dictionnaire franco-japonais, édité par Shogakukan et Le Robert, 1996 (page 2598), 2097 pages, « printed in Japan » (page 2598) ISBN 4-09-515201-X. On y trouve page 1765 une entrée « pascuan » dans laquelle la prononciation est indiquée sous la forme « [pas-kɥɑ̃] » et « [-kɥan] » pour le féminin en « ane ». Alphabeta (discussion) 23 septembre 2018 à 14:19 (UTC)
- On dit pascuense en espagnol et Pascuan en anglais ; d’où ma question incidente : ce pascuan serait-il un anglicisme ? Alphabeta (discussion) 23 septembre 2018 à 14:27 (UTC)
- Peut-être que ça vient de l’anglais, effectivement. Pour la prononciation, tous les dictionnaires cités semblent d’accord, mais ça ne veut pas dire grand chose, car il est habituel qu’ils se recopient entre eux, surtout pour ce genre de renseignements. De toute façon, le son ɥ n’existe pas plus en anglais qu’en espagnol. Je ne dis pas que c’est faux, juste que ça mérite d’être vérifié. Lmaltier (discussion) 23 septembre 2018 à 16:25 (UTC)
- Il me semble probable que Pascuan a été créé en anglais sur le toponyme espagnol (Isla de) Pascua avec le suffixe anglais formateur de gentilés -an. Le terme, passé en français, a pu se diffuser avant tout par l’écrit, d’où le ɥ … Il va sans dire que cua se prononce kwa (w) en espagnol, mais je n’ai pas trouvé d’autres termes espagnols passés en français comportant ce cua ; sinon Pascual, un prénom et nom de famille espagnol. Alphabeta (discussion) 24 septembre 2018 à 17:03 (UTC)
- Je n’ai aucune qualification pour porter un jugement global sur les dictionnaires existants, mais je pense qu’une « tournée des dicos » est souvent instructive. Alphabeta (discussion) 24 septembre 2018 à 17:17 (UTC)
- J’ai complété la liste de gentilés en -an dans l’entrée -an : ces gentilés semblent être souvent des calques de l’occitan, de l’italien, de l’espagnol ou de l’anglais : on a ainsi en français les gentilés Nigérian (le Nigeria est une accienne colonie anglaise) face à Nigérien (le Niger est une ancienne colonie française). Alphabeta (discussion) 24 septembre 2018 à 17:14 (UTC)
- Il me semble probable que Pascuan a été créé en anglais sur le toponyme espagnol (Isla de) Pascua avec le suffixe anglais formateur de gentilés -an. Le terme, passé en français, a pu se diffuser avant tout par l’écrit, d’où le ɥ … Il va sans dire que cua se prononce kwa (w) en espagnol, mais je n’ai pas trouvé d’autres termes espagnols passés en français comportant ce cua ; sinon Pascual, un prénom et nom de famille espagnol. Alphabeta (discussion) 24 septembre 2018 à 17:03 (UTC)
- Peut-être que ça vient de l’anglais, effectivement. Pour la prononciation, tous les dictionnaires cités semblent d’accord, mais ça ne veut pas dire grand chose, car il est habituel qu’ils se recopient entre eux, surtout pour ce genre de renseignements. De toute façon, le son ɥ n’existe pas plus en anglais qu’en espagnol. Je ne dis pas que c’est faux, juste que ça mérite d’être vérifié. Lmaltier (discussion) 23 septembre 2018 à 16:25 (UTC)
- Cf. https://www.youtube.com/watch?v=ykCJxI2D3ag dans cette courte vidéo de 1:54 (intitulée « Extrait du film Home - L'île de Paques ») le locuteur parle de façon relativement lente : « les Pascuans » y sont mentionnés (2 fois sauf erreur) : j’y ai cru entendre pas.kwɑ̃ plutôt que pas.kɥɑ̃ ; et vous ? Alphabeta (discussion) 25 septembre 2018 à 14:27 (UTC)
Raccourcis clavier[modifier le wikicode]
Bonjour. Y a t'il des raccourcis clavier pour naviguer à l'intérieur d'un article ? Merci d'avance. Namnète (discussion) 19 septembre 2018 à 16:45 (UTC)
- Non, aujourd'hui ce sont ceux des navigateurs Web. JackPotte ($♠) 19 septembre 2018 à 16:53 (UTC)
Boîte à idées[modifier le wikicode]
Bonjour,
Serait-il possible de mettre en place une boîte à idées sur la page d'accueil du Wiktionnaire (lien ou mini-formulaire, par exemple) ?
Pour ma part, je viens d'avoir une idée à vous proposer : que diriez-vous d'insérer en page d'accueil du Wiktionnaire un petit encadré affichant une entrée par jour à propos d'un mot / terme / locution peu usité dans la langue de tous les jours, afin d'intéresser les lecteurs à des expressions peu courantes.
On pourrait intituler cette rubrique : "Et pourtant, cela existe", "C'est pas courant" ou encore "Etonnant, non ?"
L'algorithme d'extraction des entrées peu courantes pourrait se baser sur les compteurs d'occurrences de consultation d'une entrée : chaque fois qu'un internaute affiche une entrée, un compteur d'occurrences est automatiquement incrémenté. Reste ensuite à rechercher dans la base de données les compteurs qui ont les plus faibles occurrences, ce qui revient à dire - statistiquement parlant - rechercher les entrées les moins consultées et donc les moins connues / courantes dans la langue.
On pourra éventuellement "saturer" manuellement les compteurs de termes très courants tels que, par exemple, "où", "quoi", "comment", "de", "aux", "bonjour", "bonsoir", etc, que personne ne consulte d'ordinaire, afin qu'ils n'apparaissent pas dans les extractions produites par l'algorithme (à moins qu'il ne soit plus pertinent d'au contraire présenter des expressions que tout le monde croit connaître, sans vraiment les connaître, en réalité).
En vous remerciant pour votre attention. — message non signé de 82.231.123.113 (d · c)
- Chouette idée, je suis tout pour. --Psychoslave (discussion) 20 septembre 2018 à 08:15 (UTC)
- On peut aussi piocher dans la catégorie Termes rares en français. --— Lyokoï (Discutons ) 20 septembre 2018 à 14:10 (UTC)
- Par exemple, oui. Le but de la manœuvre étant simplement d'apporter au lecteur un sujet basé sur une thématique prédéterminée, qui nourrit sa curiosité, sans le contraindre à des recherches (selon le même principe que l'article "Entrée en lumière", en mode publication automatique, si possible, présentation d'une nouvelle entrée chaque jour). Le thème lui-même pourrait changer : un mois, "Termes rares en Français", un mois, "Synonymes et compagnie", un mois, "Locutions latines", etc. --82.231.123.113 20 septembre 2018 à 15:38 (UTC)
- Pour que ça fonctionne, il faut que ça soit fait automatiquement. L’idée m’intéresse mais le problème c’est que je ne vois pas comment faire cela. Il faudrait déjà récupérer une liste des pages ayant eu le moins de visite (je ne sais pas où récupérer cette liste ni comment la générer). Ensuite, il faudrait filtrer toutes les entrées pour ne conserver que celle en français. Et après on peut changer l’entrée tous les jours en vérifiant que le mot n’a pas déjà été sélectionné précédemment (plus simple). Pamputt [Discuter] 20 septembre 2018 à 17:11 (UTC)
- Je ne sais malheureusement pas comment fonctionnent les sites wiki ni s'ils s'appuient sur des bases de données pour leurs entrées ou s'ils travaillent directement sur le système de fichiers. Je crains de n'être d'aucun secours de ce côté-là. --82.231.123.113 20 septembre 2018 à 17:52 (UTC)
- Pour les statistiques de fréquentation, Logoscope les récupère mais je ne sais pas trop comment ils font. Dans la barre latéral, Information sur la page permet d’avoir le nombre de consultation durant les 30 derniers jours, mais il nous faudrait davantage pour que ça soit intéressant, peut-être. Mais en tout cas, l’idée générale me plait bien Noé 20 septembre 2018 à 18:24 (UTC)
- Oui c’est possible d’avoir ces stats pour une page donnée. Par contre, je ne sais pas comment les avoir pour toutes les pages d’un coup car sinon il faut interroger les centaines de milliers de pages de lemmes en français, une par une, pour les obtenir et j’ai peur que ça soit un peu long. Pamputt [Discuter] 20 septembre 2018 à 18:28 (UTC)
- Pour les statistiques de fréquentation, Logoscope les récupère mais je ne sais pas trop comment ils font. Dans la barre latéral, Information sur la page permet d’avoir le nombre de consultation durant les 30 derniers jours, mais il nous faudrait davantage pour que ça soit intéressant, peut-être. Mais en tout cas, l’idée générale me plait bien
- Je ne sais malheureusement pas comment fonctionnent les sites wiki ni s'ils s'appuient sur des bases de données pour leurs entrées ou s'ils travaillent directement sur le système de fichiers. Je crains de n'être d'aucun secours de ce côté-là. --82.231.123.113 20 septembre 2018 à 17:52 (UTC)
- Pour que ça fonctionne, il faut que ça soit fait automatiquement. L’idée m’intéresse mais le problème c’est que je ne vois pas comment faire cela. Il faudrait déjà récupérer une liste des pages ayant eu le moins de visite (je ne sais pas où récupérer cette liste ni comment la générer). Ensuite, il faudrait filtrer toutes les entrées pour ne conserver que celle en français. Et après on peut changer l’entrée tous les jours en vérifiant que le mot n’a pas déjà été sélectionné précédemment (plus simple). Pamputt [Discuter] 20 septembre 2018 à 17:11 (UTC)
- Par exemple, oui. Le but de la manœuvre étant simplement d'apporter au lecteur un sujet basé sur une thématique prédéterminée, qui nourrit sa curiosité, sans le contraindre à des recherches (selon le même principe que l'article "Entrée en lumière", en mode publication automatique, si possible, présentation d'une nouvelle entrée chaque jour). Le thème lui-même pourrait changer : un mois, "Termes rares en Français", un mois, "Synonymes et compagnie", un mois, "Locutions latines", etc. --82.231.123.113 20 septembre 2018 à 15:38 (UTC)
- On peut aussi piocher dans la catégorie Termes rares en français. --— Lyokoï (Discutons
Pour ce qui concerne l’idée d’une boîte à idées, la Wikidémie pourrait servir à ça, à condition de mettre un lien particulier autre que "La Wikidémie", vraiment pas explicite. L’inconvénient est que les idées pas adoptées rapidement tomberaient dans l’oubli rapidement. On peut donc préférer avoir, plutôt qu’une boîte à idées, une page spécialisée "Vos idées", unique (pas qui change chaque mois), que n’importe qui pourrait éditer, où les idées devraient être bien classées par thèmes et sous-thèmes, non signées pour ne pas perturber la lecture (exactement avec les mêmes principes que pour l’espace principal, donc), et où on pourrait aussi rajouter les arguments manquants pour chaque idée, bien classés eux aussi. J’ai développé personnellement un logiciel de gestion des idées, je connais donc très bien la question, ce serait possible mais ça irait trop loin pour un wiki comme le nôtre. Lmaltier (discussion) 20 septembre 2018 à 17:00 (UTC)
- Je comprends. Ne connaissant rien au site (bien que lecteur / utilisateur quasi quotidien du Wiktionnaire), j'avais émis cette idée un peu au hasard. Mais bon, si c'est trop compliqué à mettre en œuvre, on oublie. --82.231.123.113 20 septembre 2018 à 17:52 (UTC)
- Ce serait bien, je suis tout à fait pour une boîte à idée sur une page non mensuelle Noé 20 septembre 2018 à 18:24 (UTC)
- Comme je n’ai sans doute pas été clair, je précise que ce que je propose ci-dessus est bien sûr tout à fait possible (sans outil particulier). Mais il ne faudrait pas appeler ça boîte à idées, les boîtes à idées, c’est autre chose, et ça ne marche pas bien. Lmaltier (discussion) 20 septembre 2018 à 18:44 (UTC)
- Ce serait bien, je suis tout à fait pour une boîte à idée sur une page non mensuelle
Activer l'espace « Reconstruction » dans les recherches par défaut[modifier le wikicode]

Enregistré sur Phabricator
T205198
Résolu
Bonjour, je ne sais pas trop comment on fait ça mais il semble qu’il faut une décision communautaire avant de faire la demande sur Phabricator. Donc petit rappel des faits. Suite à une prise de décision, l’espace « Reconstruction » a été créé pour y mettre toutes les pages de formes reconstruites. Auparavant les formes reconstruites étaient stockées dans des pages d’Annexe. La recherche dans l’espace « Annexe » est activée par défaut et on trouvait donc les pages de formes reconstruites directement. L’idée est donc de demander l’activation par défaut de la recherche dans l’espace de nom « Reconstruction » pour que l’on revienne à la situation précédente. Donc par exemple, quand on cherche « dubron », on ne trouve pas la page de la forme reconstruite tandis qu’en activant le bon espace, on trouve ce qu’il faut ![]() . Pamputt [Discuter] 20 septembre 2018 à 21:48 (UTC)
. Pamputt [Discuter] 20 septembre 2018 à 21:48 (UTC)
- Pour JackPotte ($♠) 20 septembre 2018 à 21:58 (UTC)
- JackPotte l’avait en effet remarqué dans Wiktionnaire:Prise de décision/Espace de nom : « Reconstruction »#Résultats. En fait il y a déjà eu une prise de décision là-dessus : Wiktionnaire:Prise de décision/Ajout des annexes et des thésaurus dans la recherche par défaut. Mais au moment du déplacement des reconstructions de l’espace « Annexe », la recherche par défaut n’a pas repris le nouvel espace « Reconstruction »… Donc ce serait logique de l’y remettre. — Automatik (discussion) 20 septembre 2018 à 22:05 (UTC)
- Pour Otourly (discussion) 21 septembre 2018 à 07:20 (UTC)
- Pour — Unsui Discuter 21 septembre 2018 à 07:38 (UTC)
- Pour Treehill (discussion) 21 septembre 2018 à 08:34 (UTC)
- Pour Psychoslave (discussion) 21 septembre 2018 à 08:47 (UTC)
- Pour --— Lyokoï (Discutons ) 21 septembre 2018 à 12:30 (UTC)
- Naturellement — Ltrlg (discuter), le 21 septembre 2018 à 16:32 (UTC)
- Pour Noé 21 septembre 2018 à 16:44 (UTC)
J’ai créé un ticket sur Phabricator. Pamputt [Discuter] 22 septembre 2018 à 20:01 (UTC)
Déployé ![]() --Framawiki (notifiez svp) (discussion) 24 septembre 2018 à 21:31 (UTC)
--Framawiki (notifiez svp) (discussion) 24 septembre 2018 à 21:31 (UTC)
- Super, merci ! Et pendant qu’on parle de cet espace de nom, est-ce qu’on pourrait imaginer faire comme nos collègues anglophones (section sur le modèle reconstruction), et afficher systématiquement un modèle en haut des pages dans cet espace de nom pour indiquer qu’il s’agit de pages donnant des formes non attestées ? Noé 25 septembre 2018 à 11:34 (UTC)
Utiliser « gaulois » comme code de langue pour le gaulois plutôt que « gaul »[modifier le wikicode]
Bonjour, est-ce que vous voyez un inconvénient à utiliser comme « code de langue » principal pour le gaulois le code « gaulois » au lieu de « gaul » ? Comme pour les autres langues qui n’ont pas de code ISO 639-3, on préfère utiliser le nom complet de la langue pour plus de clarté. Si on décide de faire ça, on pourra toujours continuer à utiliser « gaul » qui sera alors un alias vers « gaulois ». Pamputt [Discuter] 20 septembre 2018 à 21:54 (UTC)
- Pour JackPotte ($♠) 20 septembre 2018 à 21:59 (UTC)
- Pour aucune objection de mon côté :) Treehill (discussion) 21 septembre 2018 à 04:53 (UTC)
- Pour ##--109.212.175.188 21 septembre 2018 à 04:57 (UTC)
- le temps que je comprenne c'est quoi le code xtg
- Pour Otourly (discussion) 21 septembre 2018 à 07:18 (UTC)
- Pour — Unsui Discuter 21 septembre 2018 à 07:39 (UTC)
- Pour je serais même favorable à ce qu'un bot remplace les gaul existants par gaulois partout ou cela est pertinent. D’ailleurs je ne serais pas opposé à ce que nous fassions de même pour toutes les langues, avec la même démarche de rétro-compatibilité par alias et une transformation par bot. Mais cela va bien au-delà de la demande initiale :) --Psychoslave (discussion) 21 septembre 2018 à 08:46 (UTC)
- Pour --— Lyokoï (Discutons ) 21 septembre 2018 à 12:30 (UTC)
- Pour, si c’est l’usage ! — Ltrlg (discuter), le 21 septembre 2018 à 16:36 (UTC)
- Pour ou sinon xtg, son code ISO 639-3, non ? Noé 21 septembre 2018 à 16:44 (UTC)
- Cette remarque est intéressante. Nous possédons déjà le code "xtg" pour le gaulois transalpin. S’il s’agit de la même langue que le "gaulois" alors il faudrait fusionner le tout car pour le moment on gaulois et gaulois transalpin. Avis des spécialistes du gaulois bienvenus. Pamputt [Discuter] 21 septembre 2018 à 20:38 (UTC)
- Oui, il faudrait fusionner. Apparemment, le gaulois transalpin est ce qu’on appelle communément le gaulois. Le transalpin n’est là que pour éviter la confusion avec le gaulois cisalpin, dont la nature est discutée (voir Wikipédia). Lmaltier (discussion) 22 septembre 2018 à 19:06 (UTC)
- Cette remarque est intéressante. Nous possédons déjà le code "xtg" pour le gaulois transalpin. S’il s’agit de la même langue que le "gaulois" alors il faudrait fusionner le tout car pour le moment on gaulois et gaulois transalpin. Avis des spécialistes du gaulois bienvenus. Pamputt [Discuter] 21 septembre 2018 à 20:38 (UTC)
Finalement, j’ai redirigé « gaul » et « gaulois » vers le code « xtg » (que j’ai renommé de gaulois transalpin et gaulois). Vous êtes donc maintenant encouragé à utiliser le code « xtg » au lieu de « gaul » et « gaulois ». Pamputt [Discuter] 22 septembre 2018 à 19:53 (UTC)
- @Pamputt : Tu as du faire une erreur de redirection car tous les articles avec ’gaulois’ donne maintennt ’lepontique’ en titre, or ce n'est pas la même chose. Serait-il possible de corriger cela ? :) Merci par avance, Treehill (discussion) 22 septembre 2018 à 21:10 (UTC)
- @Treehill : en effet grosse erreur qui est maintenant corrigée. Pamputt [Discuter] 22 septembre 2018 à 21:15 (UTC)
- Super, merci beaucoup :) Bonne soirée Treehill (discussion) 22 septembre 2018 à 22:23 (UTC)
oxymores[modifier le wikicode]
Bonjour,
Ne faudrait-il pas créer une catégorie : oxymores en français ? Cordialement Gtaf (discussion) 22 septembre 2018 à 08:10 (UTC)
- Tout dépend pour combien de mots : s'il n'y en a qu'un ou deux il suffit de les mentionner dans oxymore. JackPotte ($♠) 22 septembre 2018 à 10:26 (UTC)
- J'ai déjà ajouté noyade sèche aux exemples donnés dans oxymore. Sur internet, on en trouve d'autres, comme ici, mais tous les oxymores méritent-ils d'entrer dans le wiktionnaire ? Gtaf (discussion) 22 septembre 2018 à 15:27 (UTC)
- Un oxymore est une figure de mot mais n'est pas du vocabulaire. On peut en créer autant qu'il y a de mots x 2 (et même x 4, en comptant les positions. Après il faudra lister toutes autres figures de mots, comme les métaphores, les métonymies, les litotes, et on tend vers l'infini. Ca fait beaucoup. Les figures de mots sont un sous-ensemble des figures de style. --Peyreorade (discussion) 22 septembre 2018 à 20:21 (UTC)
- J'ai déjà ajouté noyade sèche aux exemples donnés dans oxymore. Sur internet, on en trouve d'autres, comme ici, mais tous les oxymores méritent-ils d'entrer dans le wiktionnaire ? Gtaf (discussion) 22 septembre 2018 à 15:27 (UTC)
Atelier de formation au Wiktionnaire[modifier le wikicode]

Bonjour,
Dimanche 7 octobre à Grenoble, à l’occasion de la WikiConvention francophone 2018, nous proposons un atelier de formation à la contribution au Wiktionnaire. J’ai repris les diapos que je vous avais déjà présenté en mars dernier et nous avons ajouté une nouvelle partie sur l’ajout de traductions, grâce à l’aide de DaraDaraDara. Nous deux serons accompagné de Lyokoï et Ltrlg pour cet atelier, ainsi que toutes les autres personnes qui seront là et qui voudraient voir comment ça se passe un atelier, comme Assassas77 ou Geugeor. Nous imaginons former une dizaine de personnes, mais ce sera peut-être plus, peut-être moins. Nous ferons un compte-rendu de toute façon, ici ou dans les Actualités du mois prochain.
Le programme est donc d’apprendre à ajouter en 1h30 :
- Images avec l’éditeur visuel
- Attestations d’usage avec un peu de mise en forme (modèle source, gras, italique)
- Traductions (avec le formulaire puis avec l’activation de Créer-Trad)
- Synonymes et antonymes (avec présentation des sections)
- Définitions (avec les modèles de début de ligne)
- (s’il reste du temps, en extra-bonus, des diapos sur l’étymologie sont prêtes à la fin)
Nous sommes intéressés si vous avez des retours à nous faire d’ici là pour nous aider à améliorer les diapo. Si vous êtes intéressés pour ajouter une volée de diapos en plus sur un autre thème (pour une autre fois avec davantage de temps), n’hésitez pas à nous dire ! Ce document est voué à évoluer à l’avenir, et si vous souhaitez que je vous envoie le document modifiable (que Commons ne peut pas héberger), vous êtes les bienvenus pour me demander en privé ![]() Noé 22 septembre 2018 à 16:53 (UTC)
Noé 22 septembre 2018 à 16:53 (UTC)
- J’en profite pour vous faire remonter cette proposition d'intégrer les ODP à Commons: https://commons.wikimedia.org/wiki/Commons:Village_pump/Proposals/Archive/2018/07#Allow_to_upload_ODP_file_format --Psychoslave (discussion) 22 septembre 2018 à 18:38 (UTC)
- Merci Noé pour ses diapos et pour l’animation de l’atelier (je ne peux malheureusement pas être avec vous). Juste une remarque à la diapo 44, tu écris qu’on doit utiliser le modèle
{{R}}pour sourcer. Or à la diapo suivante, tu montres du code utilisant{{RÉF}}. Ce serait bien d’uniformiser. Et du coup, je pense que sur la diapo 45, il faudrait aussi montrer le code dans la section « Références ». A part çan je trouve ça très didactique. On verra plus tard pour ajouter d’autres « atelier », je pense qu’il y a suffisamment à faire pour le moment. Pamputt [Discuter] 22 septembre 2018 à 20:15 (UTC)- Merci pour ces retours ! J’ai corrigé les diapos en prenant un autre exemple qui utilise la mise en forme avec
{{R}}et non{{RÉF}}qui est considéré comme obsolète. J’attends d’autres retours éventuels avant de mettre à jour le fichier sur Commons. Ah, et puisque Vive la Rosière prévoie d’aller à la Wikiconvention aussi, peut-être qu’elle voudra animer cet atelier aussi ? Noé 23 septembre 2018 à 10:36 (UTC)
- Merci pour ces retours ! J’ai corrigé les diapos en prenant un autre exemple qui utilise la mise en forme avec
J’ai mis à jour les diapos, en ajoutant, page 16, une diapo pour montrer comment récupérer sur Wikisource la référence d’une page avec la mise en forme qui va bien pour le Wiktionnaire. Vous connaissiez ? ![]() Noé 1 octobre 2018 à 16:21 (UTC)
Noé 1 octobre 2018 à 16:21 (UTC)
- On en apprend tous les jours JackPotte ($♠) 2 octobre 2018 à 05:45 (UTC)
Présentation générale du Wiktionnaire[modifier le wikicode]

Samedi 6 octobre à Grenoble, pendant la WikiConvention francophone 2018, nous proposerons également une présentation générale du projet. J’ai repris les diapos déjà présentées deux fois, dont en janvier dernier et j’ai renouvelé quelques pages. Pas de grands changements, à part quelques stats sur les synonymes que j’ai repris de Dbnary qui en fourni plein.
Nous aurons moins de temps que précédemment, puisque nous n’aurons qu’une heure, avec au moins 10 min pour la discussion à la fin. Du coup, votre avis et votre aide nous intéresse pour corriger les erreurs éventuelles et pour nous dire ce qui vous semble le plus important et le moins important. Comme précédemment, ces diapos sont destinées à évoluer et nous apprécions grandement tous les retours que nous recevons !
Nous, c’est Lyokoï et moi normalement, mais si d’autres personnes veulent nous remplacer, c’est possible. Je serai d’autant plus motivé à laisser ma place que DaraDaraDara présentera à la même heure sur les spécificités de la contribution à Wikisource, un sujet qu’il est bien ![]() Noé 24 septembre 2018 à 08:45 (UTC)
Noé 24 septembre 2018 à 08:45 (UTC)
- Page 17 : 3 350 000 et non pas 3 500 000. Otourly (discussion) 24 septembre 2018 à 09:09 (UTC)
- C’est en précision du chiffre qu'on aura atteint à la date de la présentation Pamputt [Discuter] 24 septembre 2018 à 10:52 (UTC)
- @Otourly : blague à part, la diapo parle des entrées, pas du nombre de pages (il peut y avoir plusieurs entrées dans une seule page). Pamputt [Discuter] 24 septembre 2018 à 19:58 (UTC)
- En effet, c’est un compte des entrées et non des pages, comme dit Pamputt. Le chiffre est présenté sur la troisième ligne du tableau sur la page Wiktionnaire:Statistiques Noé 25 septembre 2018 à 07:15 (UTC)
- En effet, c’est un compte des entrées et non des pages, comme dit Pamputt. Le chiffre est présenté sur la troisième ligne du tableau sur la page Wiktionnaire:Statistiques
- C’est en précision du chiffre qu'on aura atteint à la date de la présentation
- Sur la diapo 60, je pense qu’il peut être intéressant d’indiquer en plus qu’il existe des lieux pour rencontrer des contributeurs « en vrai » (KoToPo à Lyon, premier samedi du libre à la Vilette à Paris, …). Je n’ai pas encore d’idées précises sur la façon d’indiquer cela de manière concise. Pamputt [Discuter] 24 septembre 2018 à 20:08 (UTC)
- Bonne idée, je vais réfléchir sur la forme sous laquelle présenter ça. Du coup, Psychoslave, tu prévoyais de faire des sessions wiktionnaire à Strasbourg, est-ce que tu aurais une idée de dates et lieux que je puisse annoncer ? Noé 25 septembre 2018 à 07:15 (UTC)
- La première aura lieu le 13 octobre, voir Liste des évènements de la catégorie Ateliers des médiathèques de Strasbourg. Pour les suivants, ils sont aussi déjà programmés, je laisse @Cendrars83 : fournir une référence officiel pour la date des ateliers suivant. . --Psychoslave (discussion) 25 septembre 2018 à 10:06 (UTC)
- La première aura lieu le 13 octobre, voir Liste des évènements de la catégorie Ateliers des médiathèques de Strasbourg. Pour les suivants, ils sont aussi déjà programmés, je laisse
- Bonne idée, je vais réfléchir sur la forme sous laquelle présenter ça. Du coup, Psychoslave, tu prévoyais de faire des sessions wiktionnaire à Strasbourg, est-ce que tu aurais une idée de dates et lieux que je puisse annoncer ?
Merci pour les infos pour la rencontre. J’ai mis à jour les diapos avec une liste des prochaines dates (page 69). Cette année il y a plusieurs ateliers réguliers qui intègrent le Wiktionnaire, c’est chouette ![]() Noé 2 octobre 2018 à 13:06 (UTC)
Noé 2 octobre 2018 à 13:06 (UTC)
Articles en langue bretonne[modifier le wikicode]
Bonjour, Je souhaiterais lever, une fois pour toutes, une ambiguïté concernant les pages consacrés ici au breton. Je me souviens avoir déjà posé la question qui suit à l'un d'entre vous, sans être capable de me rappeler à qui :-( :
Pour tenter d'être clair, je vais prendre le cas d'une page simple, celle du verbe paeañ. Cette page fait apparaître à deux reprises la transcription phonétique du mot concerné : la rubrique « Prononciation » est-elle réellement nécessaire ?
Meilleures salutations.--Prieladkozh (discussion) 23 septembre 2018 à 14:49 (UTC)
- Dans un tel cas, il est courant d’omettre la section « Prononciation » — qu’on ne garde que s'il y a d’autres infos à y mettre qu’une simple répétition de la prononciation déjà sur la ligne de forme. — Automatik (discussion) 23 septembre 2018 à 14:55 (UTC)
- OK, c'est noté. Ceci signifie-t-il que je dois/peux alléger les pages contenant ce genre de doublon ? J'ai finalement retrouvé la réponse qui m'avait été antérieurement faite par Pamputt.--Prieladkozh (discussion) 23 septembre 2018 à 15:21 (UTC)
- Il avait été convenu de l’omettre, pour alléger la page, sauf quand il y avait d’autres renseignements à y mettre. Mais ce n’est pas un point fondamental. Lmaltier (discussion) 23 septembre 2018 à 15:31 (UTC)
- Bien. Vous est-il possible de m'expliquer ce que vous entendez par « [...] d’autres renseignements à y mettre. » ?--Prieladkozh (discussion) 23 septembre 2018 à 16:19 (UTC)
- D’autres que la simple répétition de la prononciation déjà présente sur la ligne de forme, comme l’explique Automatik ci-dessus. Lmaltier (discussion) 23 septembre 2018 à 16:21 (UTC)
- @Prieladkozh : En fait, on met la section prononciation dès qu'il y a un audio et/ou des transcriptions de prononciations régionales. S’il n'y a sur l’article QUE la prononciation présente dans la ligne de forme, cette section n’est pas utile. --— Lyokoï (Discutons ) 23 septembre 2018 à 18:01 (UTC)
- D’autres que la simple répétition de la prononciation déjà présente sur la ligne de forme, comme l’explique Automatik ci-dessus. Lmaltier (discussion) 23 septembre 2018 à 16:21 (UTC)
- Bien. Vous est-il possible de m'expliquer ce que vous entendez par « [...] d’autres renseignements à y mettre. » ?--Prieladkozh (discussion) 23 septembre 2018 à 16:19 (UTC)
- Il avait été convenu de l’omettre, pour alléger la page, sauf quand il y avait d’autres renseignements à y mettre. Mais ce n’est pas un point fondamental. Lmaltier (discussion) 23 septembre 2018 à 15:31 (UTC)
- OK, c'est noté. Ceci signifie-t-il que je dois/peux alléger les pages contenant ce genre de doublon ? J'ai finalement retrouvé la réponse qui m'avait été antérieurement faite par Pamputt.--Prieladkozh (discussion) 23 septembre 2018 à 15:21 (UTC)
Bonjour à tous et grand merci pour ces dernières précisions. Cordialement.--Prieladkozh (discussion) 24 septembre 2018 à 07:46 (UTC)
L’enclise en italien & titre de section[modifier le wikicode]
Bonjour,
Ce sujet a déjà été évoqué ici ou là. En italien, il existe des mots composés d’une forme verbale et d’un pronom ou enclise. Par exemple : fare + lo = farlo (le faire), amare + la = amarla (l’aimer [en parlant d’une fille]) mais ça peut-être encore plus complexe dì + mi = dimmi (dis-moi) ou encore dì + mi + la = dimmela (dis-la moi). On ne peut pas parler d’une forme fléchie d’un verbe ni d’un verbe ce que pourtant ont choisit les anglophones : en:farlo ou en:dimmi. Faudrait-il créer un nouveau nom de section pour que ça corresponde au mieux à la catégorie lexicale ? Otourly (discussion) 23 septembre 2018 à 18:15 (UTC)
- Le choix des anglophones ne me semble pas choquant : en effet, c’est basé sur le verbe, et on modifie la forme du verbe concernée pour y adjoindre un pronom. Mais le point central, c’est la forme verbale, modifiée d’une certaine façon, selon des règles bien déterminées, on peut donc dire que c’est une flexion de verbe, simplement une flexion un peu spéciale, un peu plus qu’une simple forme conjuguée. Lmaltier (discussion) 23 septembre 2018 à 18:23 (UTC)
- A noter que, pour le français, on définit au comme une forme d’article défini. Cela me semble un peu plus discutable que le cas que nous discutons, mais on comprend. Lmaltier (discussion) 23 septembre 2018 à 20:02 (UTC)
- Peut-être on pourrait créer un modèle
{{enclise}}à insérer en début de définition ? Otourly (discussion) 24 septembre 2018 à 04:49 (UTC)- C’est une possibilité. Je ne pense pas que le mot enclise soit très connu, mais il est peut-être plus connu par ceux qui s’intéressent à l’italien ? Lmaltier (discussion) 24 septembre 2018 à 05:14 (UTC)
- C'est comme ça que ça s'appelle quand le pronom est collé à la fin d'un verbe. Mettre autre chose pourrait entretenir une confusion avec d'autres formes groupées de pronom. Otourly (discussion) 24 septembre 2018 à 07:09 (UTC)
- On utilise « flexion » pour puis-je. Pour moi, ton problème est similaire. --— Lyokoï (Discutons ) 24 septembre 2018 à 09:21 (UTC)
- @Lmaltier et @Lyokoï : j’ai fait un test de mise en forme là : farlo. Otourly (discussion) 24 septembre 2018 à 15:28 (UTC)
- @Otourly : Y'a moyen de mettre un lien sur Enclise ? Je pense que ça rendrait plus lisible l’information. Autrement, la mise en forme me va. --— Lyokoï (Discutons ) 24 septembre 2018 à 16:11 (UTC)
- @Lyokoï : + catégorie. & pour info l’espagnol et le catalan sont aussi concernés par les enclises. Otourly (discussion) 24 septembre 2018 à 16:48 (UTC)
- On utilise « flexion » pour puis-je. Pour moi, ton problème est similaire. --— Lyokoï (Discutons
- C'est comme ça que ça s'appelle quand le pronom est collé à la fin d'un verbe. Mettre autre chose pourrait entretenir une confusion avec d'autres formes groupées de pronom. Otourly (discussion) 24 septembre 2018 à 07:09 (UTC)
- C’est une possibilité. Je ne pense pas que le mot enclise soit très connu, mais il est peut-être plus connu par ceux qui s’intéressent à l’italien ? Lmaltier (discussion) 24 septembre 2018 à 05:14 (UTC)
- Peut-être on pourrait créer un modèle
- A noter que, pour le français, on définit au comme une forme d’article défini. Cela me semble un peu plus discutable que le cas que nous discutons, mais on comprend. Lmaltier (discussion) 23 septembre 2018 à 20:02 (UTC)
![]() @Otourly : Je vois seulement les problèmes suivants :
@Otourly : Je vois seulement les problèmes suivants :
- il faudrait que le tableau en bas apparaisse à droite, là où on a l’habitude de voir ce genre de tableau (en supprimant le titre de vocabulaire apparenté par le sens)
- il manque la majuscule en début de définition
- et surtout, on ne peut pas donner de traduction en français pour ce genre de forme : supposons seulement que le nom masculin en italien se traduise par un nom féminin en français… La bonne traduction serait plutôt la faire dans ce cas. Et la bonne traduction de far est-elle toujours faire ? J’en doute. C’est pour ça que je mettrais comme définition Contraction du verbe far avec le pronom personnel masculin. En adaptant bien sûr à chaque cas (en précisant par exemple la personne, le mode, le temps… concernés en cas de besoin). Lmaltier (discussion) 24 septembre 2018 à 17:47 (UTC)
- @Lmaltier : Bien vu. Bon reste à concevoir ce tableau qui va demander un peu de temps car je n’ai trouvé de tableau recensant toutes les possibilités. Ça va demander un peu de réflexion. Otourly (discussion) 24 septembre 2018 à 18:00 (UTC)
- J’ai été un peu vite dans mes explications. Par exemple, il faut préciser que le pronom est un pronom masculin singulier (j’avais oublié ce détail). En fait, la définition doit reprendre les éléments qui étaient dans la section étymologie, et ainsi la remplacer, comme on le fait pour toutes les pages de flexion. Ces formes sont de nature grammaticale par nature : ce sont les différentes parties de la forme qui ont un sens, plus que la forme complète elle-même. C’est donc normal que la définition soit de nature grammaticale aussi. Par ailleurs, j’ai oublié de préciser qu’il est bon de mettre un exemple d’emploi (citation, de préférence), avec sa traduction en français, pour faciliter la compréhension du procédé grammatical par ceux qui n’y connaissent rien ou quasiment rien en italien. Lmaltier (discussion) 24 septembre 2018 à 19:15 (UTC)
- Je suis assez d’accord avec Lmaltier, la définition devrait être en italique et principalement grammaticale. En revanche, le terme contraction en linguistique ne correspond pas à ça, il s’agit plutôt d’agglutination, ou bien d’enclise, bien sûr. C’est bien si ces formes peuvent intégrer le Wiktionnaire, en italien, espagnol et catalan Noé 25 septembre 2018 à 07:24 (UTC)
- @Noé : Bien noté, merci . Otourly (discussion) 25 septembre 2018 à 07:34 (UTC)
Je signale aussi le bulgare, où les articles définis sont accolés en fin de nom, et où nous donnons toutes les formes dans les tableaux de flexion. Il est vrai que c’est un cas très différent, dans la mesure où l’article n’existe que sous cette forme, qu’on peut très bien considérer aussi comme une flexion tout à fait normale (tout est question de point de vue). Pour l’italien, est-il envisageable de répertorier l’ensemble de ces formes pour chaque verbe sous forme de tableau ? Cela vaut le coup de se poser la question, je pense, et je n’ai pas la réponse. Lmaltier (discussion) 26 septembre 2018 à 05:37 (UTC)
Prononciation de nauruan (et ses formes fléchies)[modifier le wikicode]
L’entrée wikt:fr:nauruan (version [1]) indique la prononciation « \nau.ʁuɑ̃\ ». La syllabation m’interpelle : y aurait-il une erreur (au moins matérielle) ? Alphabeta (discussion) 25 septembre 2018 à 15:07 (UTC)
- En effet, c’est dégueulasse… Écrit comme ça on devrait le syllabiser \na.u.ʁu.ɑ̃\. Mais mon dico de la prononciation indique « Erreur sur la langue ! ou Erreur sur la langue ! » pour Nauru. Donc, je pense que la prononciation doit être Erreur sur la langue ! ou Erreur sur la langue !. --— Lyokoï (Discutons ) 25 septembre 2018 à 16:51 (UTC)
- Voir le « diff » [2] : la prononciation nau.ʁuɑ̃ a été ajoutée dans l’entrée le 11 janvier 2013 par Elbarriak (d · c · b) qui pourrait donc intervenir utilement ici. Alphabeta (discussion) 26 septembre 2018 à 14:15 (UTC). — PS : ce qui précède vaut pour la section Adjectif, pour la partie Nom (nom de langue) voir le « diff » [3] : le 4 mars 2012, l’IP 82.236.40.108 (d · c · b) a remplacé la prononciation no.ʁɥɑ̃ par la prononciation nao.ʁuɑ̃ ; voir aussi le « diff » [4] : le 16 septembre 2011, le bot JackBot (je ne mets pas de lien car je crois que cela provoquerait une alerte s’agissant d’un bot) a introduit la prononciation no.ʁɥɑ̃. Alphabeta (discussion) 26 septembre 2018 à 14:48 (UTC). — PPS : le bot Jackbot a pour maître JackPotte (d · c · b). Alphabeta (discussion) 26 septembre 2018 à 14:51 (UTC)
- @Alphabeta : les bots ne devinent pas la prononciation mais parfois la recopient. En l’occurrence JackBot a recopié la prononciation ajoutée par Urhixidur : [5]. — Automatik (discussion) 26 septembre 2018 à 15:07 (UTC)
- Merci à Automatik pour cette rectification ; Urhixidur est intervenu dans l’entrée le 14 février 2008 à 02:00 : ça nous rajeunit pas ! Alphabeta (discussion) 28 septembre 2018 à 18:16 (UTC)
- Voir le « diff » [2] : la prononciation nau.ʁuɑ̃ a été ajoutée dans l’entrée le 11 janvier 2013 par Elbarriak (d · c · b) qui pourrait donc intervenir utilement ici. Alphabeta (discussion) 26 septembre 2018 à 14:15 (UTC). — PS : ce qui précède vaut pour la section Adjectif, pour la partie Nom (nom de langue) voir le « diff » [3] : le 4 mars 2012, l’IP 82.236.40.108 (d · c · b) a remplacé la prononciation no.ʁɥɑ̃ par la prononciation nao.ʁuɑ̃ ; voir aussi le « diff » [4] : le 16 septembre 2011, le bot JackBot (je ne mets pas de lien car je crois que cela provoquerait une alerte s’agissant d’un bot) a introduit la prononciation no.ʁɥɑ̃. Alphabeta (discussion) 26 septembre 2018 à 14:48 (UTC). — PPS : le bot Jackbot a pour maître JackPotte (d · c · b). Alphabeta (discussion) 26 septembre 2018 à 14:51 (UTC)
- Voir le « diff » [6] : Lyokoï a corrigé les prononciations figurant dans l’entrée : merci à lui. Alphabeta (discussion) 28 septembre 2018 à 18:13 (UTC)
- Voir le « diff » [7] : j’ai ajouté dans l’entrée la prononciation \no.ʁy.ɑ̃\, attesté dans le Dictionnaire universel francophone (DUF), Hachette, 1997, 1554 pages, ISBN 2-84129-345-9, entrée « nauruan, ane », page 859 sous la forme : « noʀyɑ̃, an » : j’ai actualisé la prononciation du r et ajouté la syllabation manquante. Alphabeta (discussion) 28 septembre 2018 à 18:08 (UTC)
Bonjour, vous savez que le wiktionnaire posséde des formes d'espéranto qui, à priori, n'existe pas puisque faisant parti d'une « proposition de réforme rejetée ». Quel est l’intérêt ? --Borda (discussion) 25 septembre 2018 à 20:16 (UTC)
- Ce n’est pas le cas de enfermos, il me semble. C’est simplement la note qui est inutile. Lmaltier (discussion) 25 septembre 2018 à 20:19 (UTC)
- Y a déjà un paragraphe sur le sujet ce mois-ci : #Quel_intérêt_d’indiquer_des_formes_officiellement_rejetées_? JackPotte ($♠) 25 septembre 2018 à 20:20 (UTC)
- Merci, je découvre. J'ai lu rapidement. C’est peut-être une langue de spécialiste, en tout cas la note est tout sauf claire. J'avais vraiment compris que « enfermos » était une forme non existante de l'espéranto. --Borda (discussion) 26 septembre 2018 à 09:01 (UTC)
- Y a déjà un paragraphe sur le sujet ce mois-ci : #Quel_intérêt_d’indiquer_des_formes_officiellement_rejetées_? JackPotte ($♠) 25 septembre 2018 à 20:20 (UTC)
Compte-rendu d'activité du fantastique groupe d'utilisateurs et d'utilisatrices de Wiktionnaire[modifier le wikicode]
Bonjour,
Le fantastique groupe d'utilisateurs et d'utilisatrices de Wiktionnaire fête ses deux ans officiellement aujourd’hui, et pour cela, rend un rapport annuel d’activité. Celui-ci n’est pas très positif, malgré quelques avancées. J’ai mis pas mal d’énergie dans ce groupe à ses débuts, dans l’idée de fédérer des bonnes volontés au delà des langues, pour que nos différentes communautés puissent communiquer davantage et profiter des réflexions développées dans d’autres langues. Et finalement, de ne porter que la LexiSession et les Actualités, c’est déjà beaucoup et j’ai trouvé peu d’écho dans les autres communautés. J’ai récemment sondé l’opinion des anglophones à propos des rencontres et ils semblent bien frileux à se réunir hors des écrans. C’est étonnant quand on pense que la première rencontre entre francophones a eu lieu en avril 2006, alors que le projet n’avait que deux ans !
Bref, je ne sais pas ce que deviendra ce groupe, ni s’il a vraiment une pertinence pour lier les communautés et faire porter notre voix auprès de la Wikimedia Foundation. Si vous avez des idées ou des envies particulières à ce sujet, je serai très intéressé pour vous lire ![]() Noé 26 septembre 2018 à 09:29 (UTC)
Noé 26 septembre 2018 à 09:29 (UTC)
- Coucou,
- Je crois beaucoup en cette initiative et je suppose que l'un des soucis de la dernière année est que tu es trop seul à la porter. Je vais essayer de plus m'impliquer à ce sujet qui m'intéresse. Des rencontres internationales de wiktionnaristes constitueraient par nature un moment fort de contribution, sans doute de façon bien supérieure que sur d'autres projets (chaque mot utilisé dans chaque conversation est une occasion de vérifier sa présence dans au moins deux wiktionnaires :)). Une première étape pourrait être l'organisation d'une wikiconvention wiktionnariste et francophone. Mais l'objectif est à mon avis la création d'une WiktCon internationale (tous les deux-trois ans à terme par exemple ce serait top). --Benoît (d) 26 septembre 2018 à 09:54 (UTC)
- J’étais un peu seul, oui, et moins actif que l’année précédente, faute de temps. Très bien si tu t’y impliques ! Pour l’organisation de rencontres, j’ai du mal à y croire pour l’instant. Comme mentionné, j’ai sondé l’opinion des anglophones et il s’avère qu’ils ne sont pas très intéressés pour se rencontrer en vrai. Du coup, je pense que très peu de personnes seraient prêtes à se déplacer pour venir nous voir. Nous avons déjà discuté de l’éventualité d’organiser quelque chose à Trévoux qui soit dédié au Wiktionnaire ou avec Wikisource en plus. Mais je ne voudrais pas que ce soit seulement organisé par des francophones, je préférerai un comité plurilingue. Et il me semble que d’abord, nous devrions bosser sur la manière de présenter le projet au grand public à l’aide de support facilement traduisibles… mais même là, je ne sais pas si ça va être facile. Les anglophones ne sont pas très intéressés pour que je les aide à traduire les diapos déjà préparées pour l’atelier de la Wikiconvention francophone, par exemple Noé 26 septembre 2018 à 12:48 (UTC)
- J’étais un peu seul, oui, et moins actif que l’année précédente, faute de temps. Très bien si tu t’y impliques ! Pour l’organisation de rencontres, j’ai du mal à y croire pour l’instant. Comme mentionné, j’ai sondé l’opinion des anglophones et il s’avère qu’ils ne sont pas très intéressés pour se rencontrer en vrai. Du coup, je pense que très peu de personnes seraient prêtes à se déplacer pour venir nous voir. Nous avons déjà discuté de l’éventualité d’organiser quelque chose à Trévoux qui soit dédié au Wiktionnaire ou avec Wikisource en plus. Mais je ne voudrais pas que ce soit seulement organisé par des francophones, je préférerai un comité plurilingue. Et il me semble que d’abord, nous devrions bosser sur la manière de présenter le projet au grand public à l’aide de support facilement traduisibles… mais même là, je ne sais pas si ça va être facile. Les anglophones ne sont pas très intéressés pour que je les aide à traduire les diapos déjà préparées pour l’atelier de la Wikiconvention francophone, par exemple
- Merci pour ce compte-rendu des activités d'un groupe dont j'ignorai presque tout ! C'est vrai que j'ai aperçu ce nom plusieurs fois sans jamais creuser. J'ai suivi les projets liés pensant qu'ils étaient plus ou moins indépendants. Bravo pour cette initiative !
- Pour les améliorations, il faudrait mettre les 42 Fantastiques en exergue dans les actualités, et en parler plus explicitement dans la Wikidémie. Et éviter des phrases oulipiennes du genre « principalement à cause de l'absence de processus décisionnaires permettant de prendre une décision »
- D'un autre côté, si les autres ne suivent pas, c'est compliqué d'avancer. Romainbehar (discussion) 26 septembre 2018 à 10:09 (UTC)
- De rien, et désolé de ne pas t’en avoir parlé plus tôt. C’est un groupe qui est encore assez peu actif, bien que ses objectifs à long terme soient assez clairs. Et un groupe qui est très informel, sans règle sur la façon de prendre une décision, et c’est ce que je voulais dire avec la phrase que tu trouves oulipienne. En réalité, j’étais contre, mais s’il y avait eu discussion, il est probable qu’une majorité ai été favorable. Nous pourrons en reparler la prochaine fois que l’on se voit, et d’ici là, si le groupe te plais, n’hésite pas à ajouter ton nom à la liste des membres Noé 26 septembre 2018 à 12:48 (UTC)
- De rien, et désolé de ne pas t’en avoir parlé plus tôt. C’est un groupe qui est encore assez peu actif, bien que ses objectifs à long terme soient assez clairs. Et un groupe qui est très informel, sans règle sur la façon de prendre une décision, et c’est ce que je voulais dire avec la phrase que tu trouves oulipienne. En réalité, j’étais contre, mais s’il y avait eu discussion, il est probable qu’une majorité ai été favorable. Nous pourrons en reparler la prochaine fois que l’on se voit, et d’ici là, si le groupe te plais, n’hésite pas à ajouter ton nom à la liste des membres
Espaces de noms Conjugaison et Rimes[modifier le wikicode]
Bonjour,
Suite à la séparation des reconstructions dans un espace de nom dédié, et observant que le tableau de conjugaison et les inventaires de rimes sont de natures très différentes, je vous propose donc la création de deux espaces de noms supplémentaires, un pour Conjugaison et l’autre pour Rimes. L’intérêt premier que je vois est la possibilité d’afficher un en-tête en haut de chaque page dans ces espaces de nom, qui en précise la nature et facilite la consultation pour le lectorat. Cela permettrait également de mieux identifier les contenus et ainsi à l’avenir de mieux paramétrer un éditeur visuel qui fonctionnerait différemment selon les espaces de nom. Ces deux espaces pourraient être indexés dans le moteur de recherche dès leur mise en place (pour éviter un second vote, mettons nous d’accord dès celui-ci). Le point négatif le plus important avec cette proposition sera l’obligation de corriger les liens morts suite aux changements de noms, mais il devrait y en avoir assez peu car les liens vers les tableaux de conjugaison sont gérés par les modèles {{conjugaison}}, {{fr-verbe-flexion}} ou équivalent pour d’autres langues. Qu’en dites-vous ? — message non signé de Noé (d · c)
- Pourquoi pas mais il faudrait lancer une prise de décision. JackPotte ($♠) 27 septembre 2018 à 12:23 (UTC)
- Tu veux mettre que les tableaux dans Conjugaison ? Y'a des gens qui y mettront les flexions sans faire gaffe. Il va falloir être vigilant.
- Pour Rimes, c’est moins gênant, mais pas trop convaincu par la nécessitée du truc. --— Lyokoï (Discutons ) 27 septembre 2018 à 12:30 (UTC)
Les tableaux de conjugaison et les inventaires de rimes sont de nature très différente, ça c’est sûr, mais je ne comprends pas la raison de cette remarque : est-ce qu’on les mélangerait quelque part ? Je ne vois pas. Actuellement, les tableaux de conjugaison sont dans des annexes, je ne vois pas quel problème ça pose. Lmaltier (discussion) 27 septembre 2018 à 18:00 (UTC)
- Je n’ai pas trop d’avis sur la question, je suis ni pour (je ne vois pas trop l’intérêt) ni contre (je n’ai pas de raison de m’opposer), donc faites comme vous voulez. Cela dit, un autre argument en faveur de tels espaces de noms et que l’on peut rechercher uniquement dans ces espaces s’ils existent. À voir si ça a un intérêt de ne filtrer que les résultats de conjugaisons ou que les résultats de rimes. Pamputt [Discuter] 27 septembre 2018 à 20:34 (UTC)
Compte rendu trimestriel sur les liens[modifier le wikicode]
Bonjour,
Au risque d’ennuyer j’effectue un nouveau compte rendu trimestriel (la dernière fois était Wiktionnaire:Wikidémie/juin 2018#Compte rendu trimestriel sur les liens, § 31 du mois Wiktionnaire:Wikidémie/juin 2018). Qu’on se rassure : si je continue ce type de travail en 2019, ces comptes rendus ne seront probablement plus que semestriels… ![]()
Voir donc (j’ai arrêté les comptes un peu avant l’heure) Utilisateur:Alphabeta/Liens WPWT créés en 2018#troisième trimestre 2018 (section de la page Utilisateur:Alphabeta/Liens WPWT créés en 2018 : voir le sommaire) : j’ai supplée à 300 cas (d’absence de lien WT-WP ou WP-WT) durant le troisième trimestre de 2018 contre 240 cas durant le trimestre précédent de 2018 et 188 cas durant ce même trimestre de 2017 : pas dit que ce travail touche à sa fin donc. Les manques constatés sont le plus souvent dans le sens « WP vers WT » : les rajouts effectués donnent davantage de visibilité pour le WT au sein de WP.
Cette activité avait débouché sur une autre : compléter les listes de dérivés et autres figurant dans les entrées du WT. (Je m’étais lancé là-dedans il y a un certain temps déjà, après être passé à côté de wikt:fr:fier comme un bar-tabac, simplement parce que cette locution n’était pas mentionnée dans wikt:fr:bar-tabac.) Même si je n’ai pas effectué de comptage général, j’ai effectué de nombreux rajouts, dont la création de Annexe:Dérivés en français de l’adjectif blanc (D H L). L’entrée wikt:fr:grand a été complétée lentement (voir le « diff » [8]), sans que l’on puisse limiter les accès en modif à cette page. Un comptage a été uniquement effectué pour les verbes dérivés en re-/ré- : 4 cas pour juillet, 80 cas pour août et 62 pour septembre (144 donc pour le trimestre).
Ces rajout de « dérivés » parfois pu parfois donner à une relecture des entrées concernées : par exemple 10 renommages (apostrophe typographique, capitalisation, etc.) ont été effectuées en août.
Cord. Alphabeta (discussion) 28 septembre 2018 à 13:38 (UTC)
- Moi je trouve ça cool. Merci ! --— Lyokoï (Discutons ) 28 septembre 2018 à 17:47 (UTC)
- Pour les liens Wikipédia vers Wiktionnaire, c’est sûr qu’on est pas prêt à en voir le bout ! Le nombre de pages ne cesse de croître et ce n’est pas dans l’habitude des gens que de mettre des liens vers le Wiktionnaire, d’autant plus maintenant que le modèle Autres projets a été en grande partie supplanté par des liens gérés par Wikidata. J’en ajoute de temps en temps, mais nettement moins que toi. Bravo donc pour ça !
- Pour les dérivés, j’ai vu plusieurs fois dans mes modifications récentes que tu faisais ça, et c’est génial. C’est une action nécessaire pour espérer pouvoir un jour organiser des Wikiwars sur le Wiktionnaire ! C’est un jeu où il faut aller le plus rapidement possible vers une page uniquement grâce aux liens contenus dans la page. Sans les dérivés, synonymes, mots apparentés, c’est tout bonnement impossible Noé 1 octobre 2018 à 14:56 (UTC)
Puces rouge et blanc[modifier le wikicode]
Bonjour, que signifient ces puces dans les historiques des versions, s'il vous plaît ? --Peyreorade (discussion) 30 septembre 2018 à 14:45 (UTC)
- Je pense que c’est lié à la liste de suivi. Otourly (discussion) 30 septembre 2018 à 14:57 (UTC)